Welcome to the Single Board Cluster Competition 2026.
This site will contain all relevant info for competitors in terms of submissions and other logistics. For time-based announcements this site will reflect it when the time rolls over according to PST – teams in forward time zones will be notified of specifics according to their local timezone.
The Single-Board Cluster Competition (SBCC) is a competition where teams from all around the world compete using single-board devices, and other similarly simple hardware, to create miniature supercomputing clusters. SBCC26 is the fourth competition.
SBCC LIVE Happening Friday/Saturday (10/10-10/11)! Click here to watch the competition live!
Schedule
Agenda:
| DAY | START | END | ACTIVITY |
|---|---|---|---|
| Thursday | 8:00 am | 8:00 am (Friday) | Setup |
| Friday | 8:00 am PDT | 8:30 AM PDT | Opening Ceremony |
| Friday | 8:00 am | 1:00 pm | Benchmarking |
| Friday | 12:00 pm | 5:00 pm | Competition Begins - Applications |
| Saturday | 8:00 am | 3:00 pm | Final Submissions Due |
| Saturday | 5:00 pm PDT | 6:00 pm PDT | Awards Ceremony |
Notice that you can submit benchmarks one hour after application details are revealed. Here is the FULL schedule
FAQ
What is the price limit for the hardware?
- 6000 USD, Use american MSRP for hardware cost when possible.
What is the power limit for the cluster?
- 250 Watts
Are eGPUs allowed?
- Yes
Does a DHCP server count as part of the cluster?
- No, given that it is only used for managing the cluster network / accessing the cluster.
Can we use LLMs during the competition?
- Yes. Only sharing information and getting advice from with mentors and individuals outside the competition should be avoided/not done. Communication in between teams and judges is allowed. Teams may also access the internet on their own computers, but not speak about the competition to others.
Can we wirelessly access our cluster during the competition?
- No. Only wired access into your cluster is allowed. This is to prevent access during the night.
Join our Discord!
Teams
| Team | ORGANIZATION | LOCATION | TEAM MEMBERS |
|---|---|---|---|
| Aalborg Supercomputer Klub | Aalborg University | Aalborg, Denmark | Brian Ellingsgaard; Emil Kristensen Vorre; Sofie Finnes Øvreild; Tobias Sønder Nielsen |
| Crossroads Coders | Indiana University; Purdue University | Indiana, USA | Sky Angeles; Gautam Hari; Tri Nguyen; Ryan Jacobson; Dominic Yoder |
| GigaDawgs | Mississippi State University | Starkville, MS, USA | Isha Shrestha, Jamie Anderson, Kavya Gautam, Travis Greene, Anoop Mishra, Soyab Karki, Edward Cruz, Niraj Gupta |
| HPC Brazil Force | Federal University of Pampa; Federal University of Rio de Janeiro; UNICAMP; Federal University of Santa Maria | Brazil | Mariana Fernandes Cabral; Mariana Rodrigues Padilha; Julio Nunes Avelar; Bruna da Silva Righi |
| KU Supercomputing Club | University of Kansas | Lawrence, KS, USA | Wyatt Sullivan; Barret Brown; Ruben Pino-Martinez; Adam Berry; Ky Le |
| Not So Slow Slugs | University of California, Santa Cruz | Santa Cruz, CA, USA | Myles Hallett; Julien Lee; Caleb Lin; Brock Morishige; Holden Martinez; Jason Waseq; Indira Maria; Shiloh Sharmahd |
| NTHU | National Tsing Hua University | Hsinchu, Taiwan | Guan-Yu Ji; Ming-Yang Zheng; Chien-Lin Li; Jonathan Tian Hsu; Ke-Ying Chen |
| Penguin Warriors | University of California, San Diego; San Diego Supercomputer Center | La Jolla, CA, USA | Ryan Estanislao; Ilias Lahdab; Rahul Chandra; Randy Bui; Aidan Jang; William Wu; Pengxiang Li; Owen Cacal |
| PlumJuice | Sapienza University of Rome | Rome, Italy | Jacopo Mazzatorta; Pietro Piccolo; Alessandro Milos; Jacopo Rallo |
| RAMbo Clements | Clemson University; Coastal Carolina University | South Carolina, USA | Jacob Davis; Caleb Johnson; Anjali Perera; Nicholas Kimmel; Adam Niemczura; Tolga Bilgis; CJ George; Ryon Peddapalli |
| Team Kent Ridge | National University of Singapore | Singapore | Tze Rui Koh; Joel Chong; Mande Neil Ashvinikumar; Lau Zhe Wen; Muhammad Asyraf Bin Abdul Rahim; Chan Dong Jun; Shubhan Gabra; Tan Yong Xiang; |
| Tech Titans | University of Botswana | Gaborone, Botswana | Chandapiwa Malema; Theo Kgosiemang; Pholoso Lekagane; Mehedi Hasan Mahin; Ray Mcmillan Gumbo; Jonathan Mosoma |
| Those Who Node | University of California, San Diego; San Diego Supercomputer Center | La Jolla, CA, USA | Cecilia Li; Tom Lu; Chanyoung Park; Chetan Totti; Ibrahim Altuwaijri; Yixuan Li; Aidan Tjon; Yuting Duan |
Aalborg Supercomputer Klub
Aalborg University

Diagram
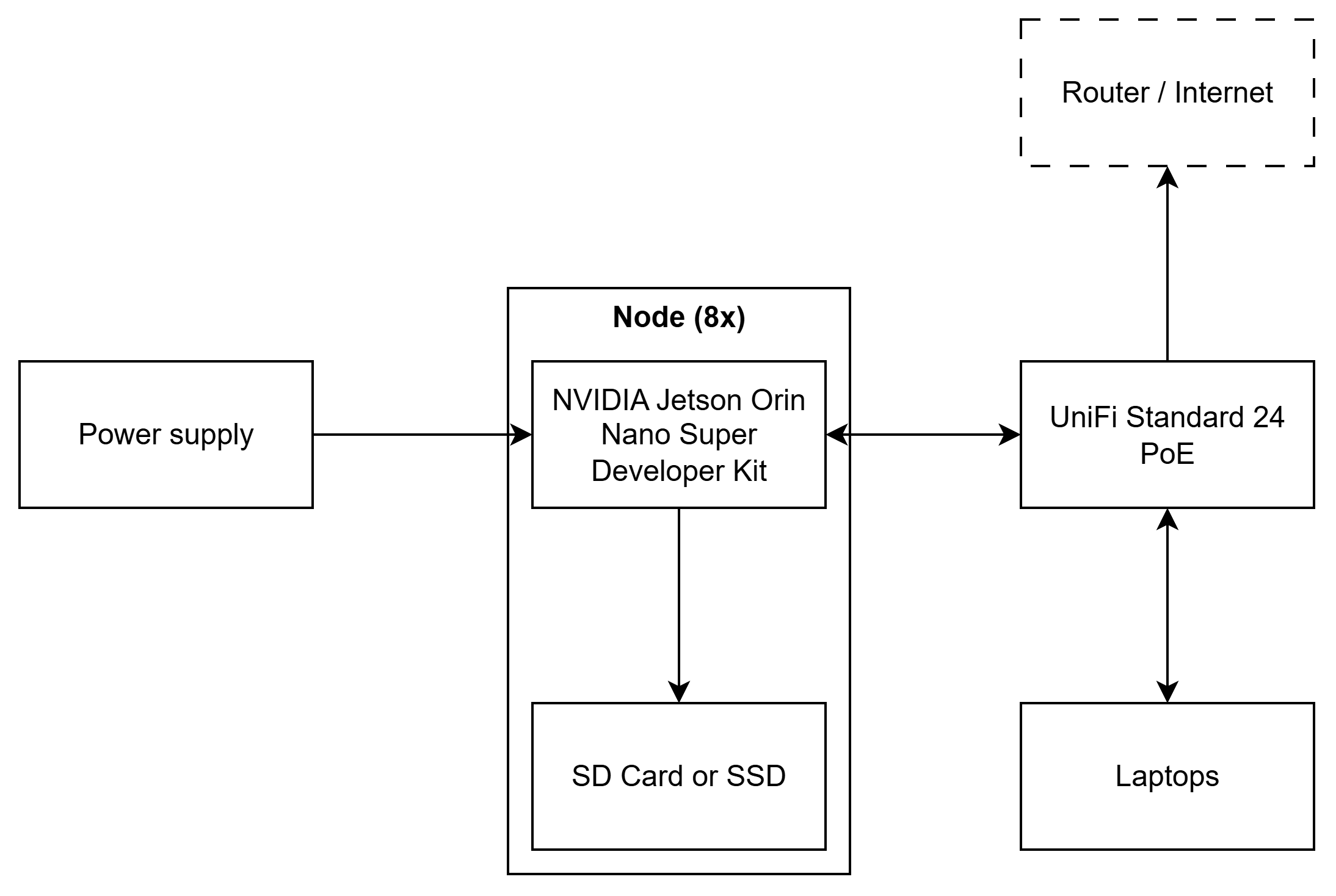
Hardware
Power monitoring
We will livestream and record footage of a wattmeter measuring the power usage of our cluster.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| NVIDIA Jetson Orin Nano Super Developer Kit | 8 | Single-board computer | 200 W | $1,992.00 |
| UniFi Standard 24 PoE | 1 | Network switch | 50 W | $349.00 |
| 2x Amazon Basic microSDXC - 64 GB [1] | 2 | SD card (2x per unit) | N/A [2] | $78.25 |
| SanDisk Extreme microSDXC - 64 GB [1] | 4 | SD card | N/A [2] | $111.96 |
| PNY CS1030 250 GB [1] | 8 | SSD | N/A [2] | $569.88 |
| Meanwell UHP-350-12 | 1 | Power supply | N/A [3] | $80.94 |
Total: $2,612.15-2,991.82 [1]
Notes:
- It is to be determined whether we go with SSDs or SD cards. Total is shown for both options.
- This is attached to a node, and included in its power draw.
- This provides power to the nodes, and so is accounted for in their power draw.
Software
Strategy
Operating system: NVIDIA Jetson Linux 36.5 - Optimized for our hardware
MPI:
- NVIDIA HPC-X MPI - Open MPI implementation specifically designed for NVIDIA hardware
- Open MPI - Fallback
BLAS:
- cuBLAS - Can take advantage of GPUs through CUDA
- BLIS - Fallback, can build BLAS library specially optimized for our CPU
Compiler:
- nvcc - CUDA
- mpicc - MPI
- Clang - C/C++
Network file share: NFS - Gets the job done. Where speed is critical, files can be copied to each node.
Cluster management:
- Ansible - Declarative, consistent and idempotent configuration across nodes
- OpenSSH - Remote access
Benchmarks
Explain your initial strategy for completing the benchmarks.
- HPL: Run the NVIDIA HPC Benchmarks implementation of HPL.
- D-LLAMA: Try to port it to cuBLAS to run on the GPU with CUDA. Alternatively attempt to run it through Vulkan, and failing that, run it on the CPUs.
- MDTest: Run with local IO to optimally utilize disk performance and avoid network overhead.
- IQ-TREE: Optimize using the documentation on the IQ-TREE website.
Applications
Not sure what the difference is between this and “Benchmarks”.
Team Details
- Brian Ellingsgaard: Loves library interface design, array-oriented programming, and theoretical computer science related to group and information theory.
- Emil Kristensen Vorre: Enjoys programming with a purpose in mind. Knowledgeable about Linux.
- Sofie Finnes Øvreild: Well-experienced with Linux and focusing on learning tooling around superclusters. Some experience with traditional software development with C/C++.
- Tobias Sønder Nielsen: Experienced with Linux and basic networking. Interested in hardware and generally toying with computers.
Crossroads Coders
Indiana University / Purdue University

Diagram
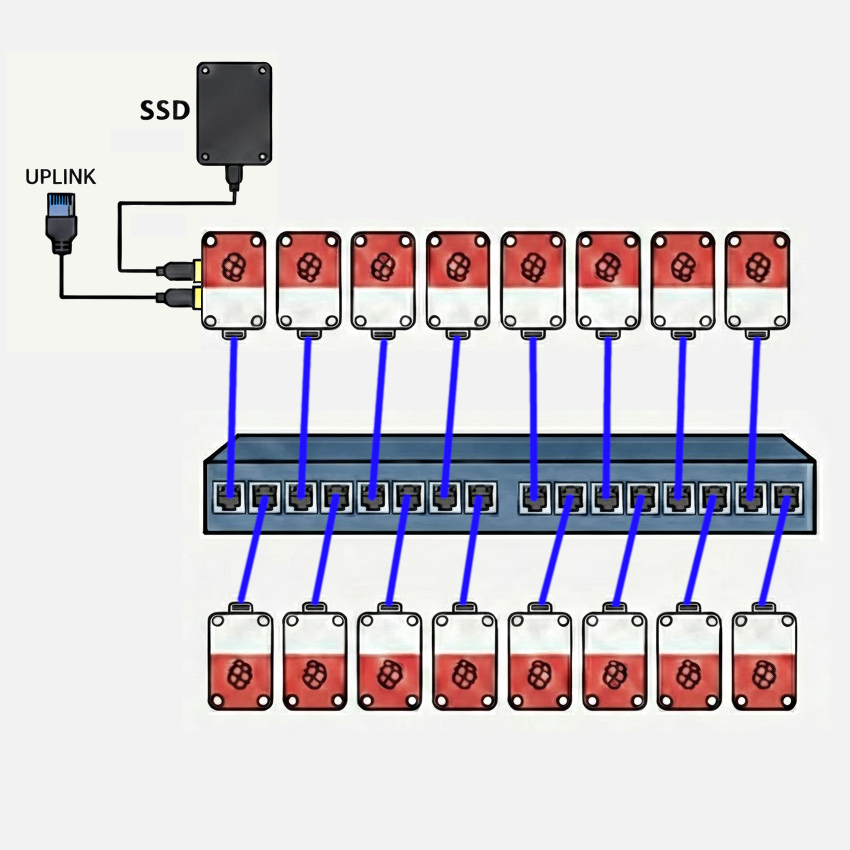
Hardware
Our team is running a 16-node Raspberry Pi 5 cluster with 8 GB nodes, a 1 GbE interconnect using an unmanaged 16-port Netgear switch. A 4 TB NVMe SSD mounted via USB 3.0 on the head node provides storage to the cluster via NFS. Access to the cluster is managed via SSH by way of a second 1 GbE USB 3.0 adapter on the head node. The USB 3.0 ports on the Raspberry Pi 5 support individual connections at up to 5 Gbit/s. The cluster power is monitored by a single Shelly Gen4 smart plug, which provides web accessible RPC monitoring of power draw parameters. The cluster is powered by individual Raspberry Pi 5 USB-C power supplies from a power strip fed from the smart plug. Each node is cooled with an active cooler with fan, available for the Raspberry Pi 5.
The primary choice for the hardware configuration was price and ratio of processing power to electrical draw. The Raspberry Pi 5 is an excellent computer for both its price-performance and performance-power-draw ratios. It fits squarely in the COTS paradigm established by the first Beowulf clusters. With the exception of GPU acceleration, this cluster is quite capable for its cost of less than $2500.
Power monitoring
The expected power draw of the cluster at full load is estimated to be less than 245 W. We will provide a live updated graph of the power usage history over the required timeframe with code that pulls the power draw data at regular intervals, as JSON-formatted output. We will provide a URL to the event organizers to keep track of this data throughout the competition.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| Raspberry Pi 5 (8GB) | 16 | Cluster Nodes (Head node + 15 compute nodes) each including active cooler, RTC battery, case and power supply | 208 W (13 W/node) | $2,031.20 ($126.95/node) |
| NETGEAR 16-Port Gigabit Ethernet Unmanaged Switch (JGS516) | 1 | Cluster Interconnect | 25 W | $97.89 |
| CAT-6 Ethernet Patch Cables | 16 | Cluster Interconnect | 0 W | $68.96 |
| USB-to-1GbE Adapter | 1 | Network Uplink (Head Node) | 2 W | $22.99 |
| Samsung Pro 990 NVMe SSD (4 TB) + Sabrent EC-RGBG USB 3.2 Enclosure | 1 | Cluster Storage (Head Node NFS Server) | 8 W | $303.25 |
| Total | 243 W | $2,524.29 |
Software
The team is still working with Raspberry Pi OS Lite (minimal/server), which provides straightforward setup and hardware compatibility with all the features of our cluster. However, we’re planning to compare the experience with Rocky Linux, knowing that it is a defacto standard in the world of HPC clusters. Ultimately, we expect to use Rocky Linux, so that we can make use of it’s compatibility with effectively all elements of the typical HPC software stack, as well as repositories of pre-built and version-matched HPC packages. The team has experience with both apt and dnf/yum package management systems, and has experimented with both for the IndySCC event at SC25.
Strategy
Our team is composed of five members of a six-person team which competed in the IndySCC (student cluster competition) at the SC25 conference. That event used the NSF ACCESS Jetstream 2 cloud infrastructure, allowing teams to create clusters of virtual machines. Our strategy is similar to that we used for the IndySCC. We plan to identify those activities we each feel most comfortable with, playing to our individual strengths, while working in pairs, so that nobody is stuck with a difficult task and nobody to discuss it with. We have found this strategy to work well, and it allows us to work in different pairing on different elements of cluster configuration, software building, and program execution. We also know that this approach doesn’t leave the team without a person who knows how to do any particular task, in the event that a team member is sick or otherwise unavailable. You might think of it as cross-training.
Benchmarks
We apply the same paired approach to building and running benchmarks. In preparation for the IndySCC, we practiced building and configuring the HPL benchmark. We also built several other benchmarks to look at parallel code performance in algorithms with less-than-perfect scaling and which were memory-bound and I/O-bound, rather than compute bound like the HPL dense matrix problem. It was also helpful to look at build processes beyond simple Makefiles.
Applications
Again, our paired approach to working on multiple applications, both building them and running them, has proven to be the best strategy in the one competition in which our team has participated. Admittedly, this can become a situation where one pair of students completes their task quickly and is able to help solve challenges faced with another application. This was certainly true in the IndySCC, where the balance of work to build applications was significantly unbalanced.
Team Details
- Sky Angeles - Sophomore Computer Science major, Indiana University
- Gautam Hari - Senior Computer Science major, Indiana University
- Tri Nguyen - Senior Computer Science major, Indiana University
- Ryan Jacobson - Senior Computer Science major, Indiana University
- Dominic Yoder - Senior Computer and IT major, Purdue University
Gigadawgs
Mississippi State University

Diagram
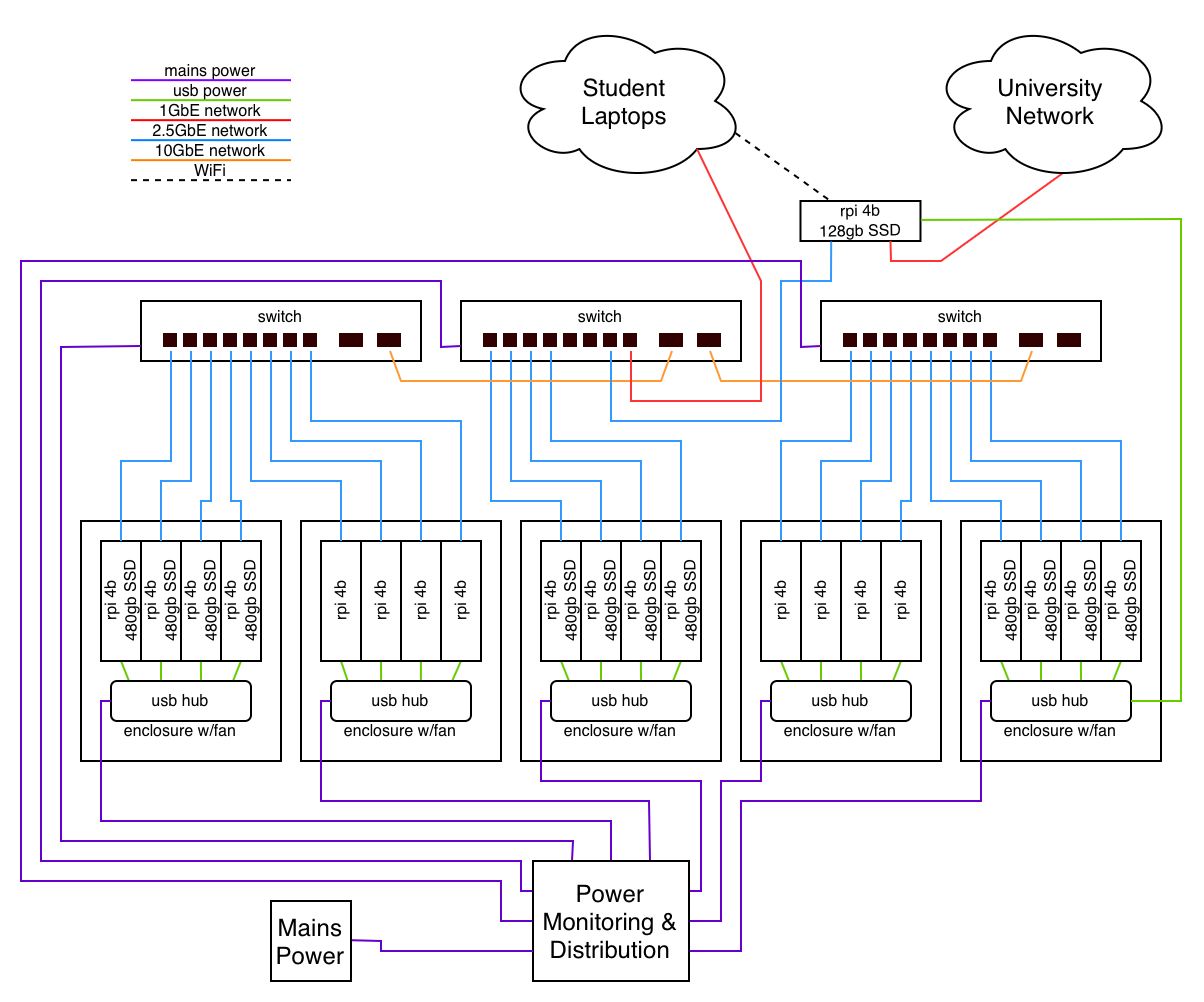
Hardware
Hardware was selected based on budget, availability, and our familiarity with the platform. The design builds on a configuration the student organization has successfully used before, ensuring compatibility with the internal documentation and tooling we’ve already developed.
A key design decision was to prioritize improved networking capabilities over the built‑in networking found on standard Raspberry Pis. In multi‑node computing, the Pis themselves are rarely the primary bottleneck, network throughput and latency usually are. Strengthening the network layer therefore provides a more meaningful performance gain.
Additionally, storage is distributed across the cluster to enhance overall performance and resilience, with several Raspberry Pis serving as both compute and storage nodes.
Power monitoring
The current plan for power monitoring is to use a Kill‑A‑Watt meter connected at the point where the cluster and its networking equipment draw mains power, with its readings livestreamed for real‑time observation.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw/Unit (W) | Price/Unit (USD) |
|---|---|---|---|---|
| Raspberry Pi 4B 4GB | 21 | Compute/Head | 7 | 75 |
| GigaPlus 8x2.5GbE/2x10Gsfp Ethernet Switch | 3 | Interconnect | 15 | 65 |
| 2.5GbE USB NIC | 21 | Interconnect | 10 | |
| 10GbE SFP+ DAC | 2 | Cabling | 10 | |
| 128GB M.2 Sata drive | 1 | Head Storage | 45 | |
| SATA Cable USB cable | 12 | Cabling | 10 | |
| 480gb sata ssd | 12 | storage | 99 | |
| 1ft cat6 patch cables | 21 | cabling | 2 | |
| usba-c cables | 21 | cabling | 1.5 | |
| usb charger | 5 | power | 26 | |
| pi4 cluster enclosure w/ fan | 5 | chassis/cooling | 1.5 | 70 |
| Pi4 enclosure w\ headsink & fan | 1 | chassis/cooling | 0.25 | 40 |
Software
| Purpose | Software Name |
|---|---|
| Operating System | Rocky Linux 9.5 Kernel: 5.14 |
| C/C++ Compiler | GNU Compiler Collection |
| Job Scheduler | Slurm |
| MPI Implementation | OpenMPI, mpi4py |
| BLAS Implementation | OpenBLAS |
| Package Managment | RPM, Spack |
| Booting System | WareWulf |
Strategy
Benchmarks
HPL: Perform an N and NB parameter sweep to identify the optimal problem size that maximizes TFLOPS.
D-LLAMA: Evaluate the trade-offs between 4-bit/8-bit quantization to achieve the highest possible token-per-second throughput for Llama 3 8B.
MDTest:Tune the parallel file system metadata servers and experiment with directory stripping to maximize IOPS for file creation and stat operations.
Applications
IQ-TREE: Implement a hybrid MPI+OpenMP execution model to minimize communication overhead while maximizing core utilization during complex phylogenetic tree reconstructions.
Mystery Application: Assign a 2-3 person team based on the individual strengths of the team members.
Team Details
| Name | Skills | Competition Responsibilities |
|---|---|---|
| Jamie Anderson | - Hardware Configuration - Basic Networking - OS Installs - Software Troubleshooting | - Helping with hardware and OS/software configuration - Helping administer system to rest of the team |
| Isha Shrestha | - AI/ML - Distributed Computing - Data Science | - Helping with D-LLAMA, MDTest and IQ-TREE |
| Edward Cruz | - Software & Environment Mgt. - Performance & Res. Monitoring - Storage & Filesystems | - Helping with IQ-TREE and MDTree |
| Niraj Gupta | - AI/ML - Data Science - Computer Vision | - Helping with HPL |
| Soyb Karki | - Distributed Systems - Software Engineering - AI | - Helping with HPL and MDTest |
| Kavya Gautam | - AI/ML - Distributed Computing - Data Science | - Helping with D-LLAMA |
| Anoop Mishra | - AI/ML - Data Science - Linux | - Helping with IQ-TREE |
| Travis Greene | - Hardware & Software Configuration - Networking - OS Install & Config - LDAP - Build Systems | - Sysadmin, install & configuration - LDAP & permissions - Cluster communication |
HPC Brazil Force
Federal University of Pampa / Federal University of Rio de Janeiro / UNICAMP / Federal University of Santa Maria

Diagram
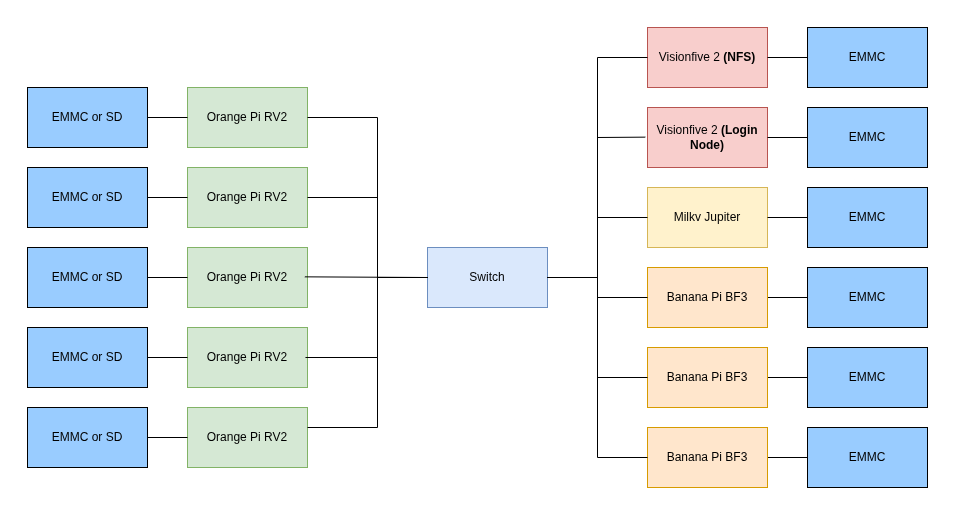
Hardware
The hardware is composed of a mix of single-board computers, including: 1x Milky Jupiter, 3x Banana Pi BF3, 5x Orange Pi RV2, 2x Visionflove 2. The hardware was chosen based on student availability and cross-compatibility. The boards with lower processing capacity are used for support functions, such as the Login Node and service provisioning, including NFS. The boards with higher computational power, in turn, act as compute nodes and are responsible for executing the cluster workloads.
Power monitoring
The cluster’s power consumption will be measured using an external wattmeter connected between the power supply and the system. The device will measure the total power draw of the entire cluster during benchmark execution. Readings will be monitored in real time on the wattmeter display. For transparency, we can provide livestreamed or recorded video of the display during the runs, allowing the committee to validate the measurements. We are available to adjust the reporting format as requested by the committee.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw (per unit) | Approx. Price (per unit) |
|---|---|---|---|---|
| Milky Jupiter - 16GB | 1 | High-performance worker node | 15–25W | $150–200 |
| Banana Pi BPI-F3 - 8/16GB | 3 | High-performance worker nodes | 8–15W | $80–110 |
| Orange Pi RV2 - 8G | 5 | Standard worker nodes | 5–10W | $40–60 |
| VisionFive 2- 8G | 2 | Login node, NFS, DHCP and other services | 5–10W | $70–90 |
| HP 1410-24G Gigabit Switch | 1 | Network Switch | 22W | $250-320 |
| 16GB EMMC Module | 3 | Storage for SBCs | $25-30 | |
| 32GB SD Card | 8 | Storage for SBCs | $5-7 | |
| 12V power suply | 9 | Power supply for SBCs | $3-4 | |
| 5V power suply | 2 | Power supply for SBCs | $3-4 |
Software
The cluster runs a fully RISC-V software stack based on open-source tools.
Linear Algebra
- BLAS: OpenBLAS
Compilers
- GCC
- G++
- MPICC
- MPIC++
MPI
- Open MPI
Build System
- CMake
Operating Systems
-
Bianbu 25.04 (Ubuntu 25.04–based distribution by Spacemit) Used on:
- Milk-V Jupiter
- Banana Pi BPI-F3
- Orange Pi RV2
-
Debian 13 Used on:
- VisionFive 2
All software components are compiled natively for RISC-V with architecture-specific optimization flags.
Strategy
Benchmarks
- High-Performance Linpack (HPL)
We intend to conduct a systematic parameter exploration across different quantities of core machines, focusing on identifying optimal configurations for HPL performance. This preliminary phase will combine theoretical algorithm analysis with empirical validation, using the HPL documentation tuning guidelines as a reference. The main objective is to find the best parameter values, especially for block size (NB), process grid dimensions (P × Q), factorization methods, and broadcast algorithms, which seem to have a significant impact on performance.
- D-LLAMA
For this benchmark challenge, we will adopt an approach similar to that used for HPL, testing parameters and different configurations exploratorily to identify the combination that delivers the best performance.
- MDTest.
To achieve the best performance in MDTest, we plan to explore different numbers of MPI processes and workload sizes, adjust filesystem configurations such as directory striping, and test multiple distribution strategies across nodes. We will also minimize background activity and repeat runs to ensure consistent and reliable results.
Applications
-
IQ-TREE Application The team will utilize MPI to parallelize IQ-TREE, aiming to reduce communication overhead and improve workload distribution across nodes.
-
Mystery Application The team will collaboratively analyze the assigned software and determine the most effective deploym# HPC Brazil Force
Team Details
Bruna Righi: Interested in HPC and eHealth. Research focuses on current eHealth developments and improvements.
Julio Avelar: Interested in computer architecture, digital systems design, and HPC. Research focuses on scalable verification and categorization of open- source RISC-V processors.
Mariana Fernandes: Research in concurrent systems testing. Interested in high-performance green computing. Already working in the technology area with experience in debugging.
Mariana Padilha: Interested in IoT and HPC. Her research focuses on flow simulation in porous media using Fortran, OpenMP/C, and CUDA.ent strategy for the cluster.
KU Supercomputing Club
University of Kansas

Diagram
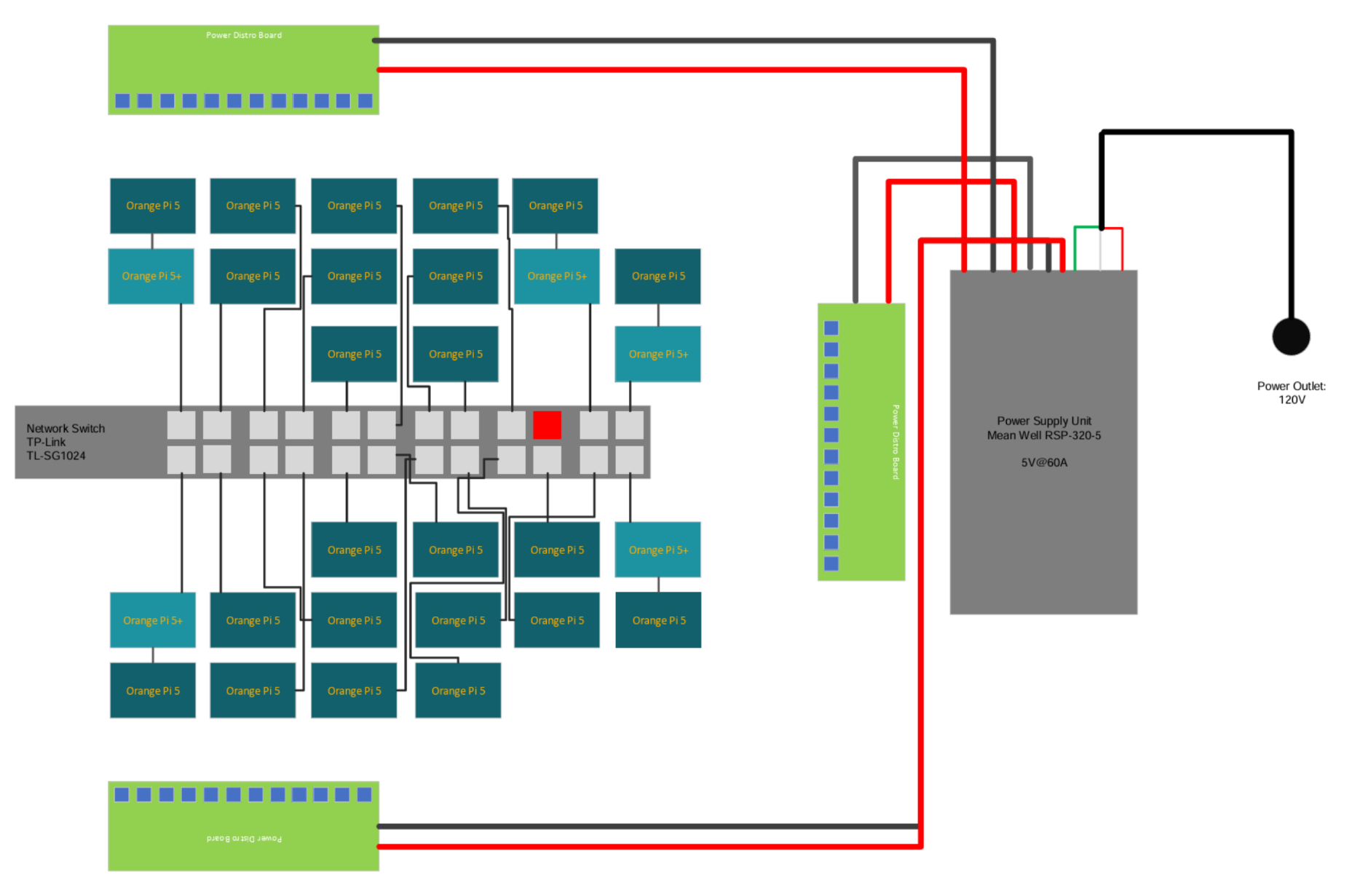
Hardware
- Bill of Materials (BOM) Below is a table describing our cluster’s hardware BOM, with network hardware included:
| Item | Cost (per unit) | # Items | Total Cost | Product Link |
|---|---|---|---|---|
| Power Supply | $36.19 | 1 | $36.19 | Amazon |
| Ethernet Switch | $89.99 | 1 | $89.99 | Amazon |
| Power Strip | $8.99 | 1 | $8.99 | Amazon |
| Power Distribution Board | $38.00 | 3 | $114.00 | Amazon |
| Power Monitor | $15.99 | 1 | $15.99 | Amazon |
| Ethernet cable (grey, 100ft) | $60.00 | 1 | $60.00 | McMaster |
| 14AWG supply wires (Black/Red, 50ft) | $23.16 | 2 | $46.32 | McMaster |
| 24AWG supply wires (Orange, 50ft) | $6.15 | 1 | $6.15 | McMaster |
| 24AWG supply wires (Black, 50ft) | $6.15 | 1 | $6.15 | McMaster |
| Ethernet RJ45 connectors (10-pack) | $10.55 | 10 | $105.50 | McMaster |
| Heatsinks | $8.99 | 15 | $134.85 | Amazon |
| Orange Pi 5+ | $289.99 | 5 | $1449.95 | Amazon |
| Orange Pi 5 | $269.99 | 14 | $3779.86 | Amazon |
| TOTAL COST | $5853.94 |
- Hardware & Network Notes
- Internet Connection: On our diagram the Red Ethernet Port is strictly reserved for the cluster’s internet connection only.
- Power Efficiency: Estimated maximum power consumption for the cluster is approximately 171.3W.
Software
| Feature | Software Used |
|---|---|
| Operating System | Armbian Linux 25.8.1 Bookworm CLI (Kernel 6.12.55) |
| C/C++ Compilation | GNU Compiler Collection (GCC) |
| Job Scheduling | Slurm |
| MPI Implementation | MPICH |
| BLAS Implementation | OpenBLAS |
| Package Management | Spack / APT |
Strategy
- HPL: Focus on OpenMP support within OpenBLAS to reduce intra-node communication overhead.
- D-LLAMA 3 8B: Compare BLAS implementations and evaluate quantization benefits for the cluster setup.
- MDTest: Experiment with tuning on a base POSIX file system.
- IQ-TREE: Utilize official documentation and tutorials for education and execution.
- Mystery Application: Research the provided application to ensure completion within the allotted time.
Team Details
Our team is comprised of five (5) University of Kansas (KU) undergraduate students that are active members of KU’s Supercomputing Club. Below is the team roster and member backgrounds:
| Name | Background |
|---|---|
| Adam Berry (Captain) | Senior in Computer Science, Software Dev. |
| Alex Rawson | Junior in Computer Science, President of Information Security Club. |
| Barret Brown | Senior in Computer Science, Software Dev. |
| Ruben Pino-Martinez | Junior in Computer Science, Applied Computing/Arduino Research. |
| Wyatt Sullivan | Undergrad student, Computing and Physics focus. |
| Ky Le | Masters Student. |
Not So Slow Slugs
University of California, Santa Cruz

Diagram
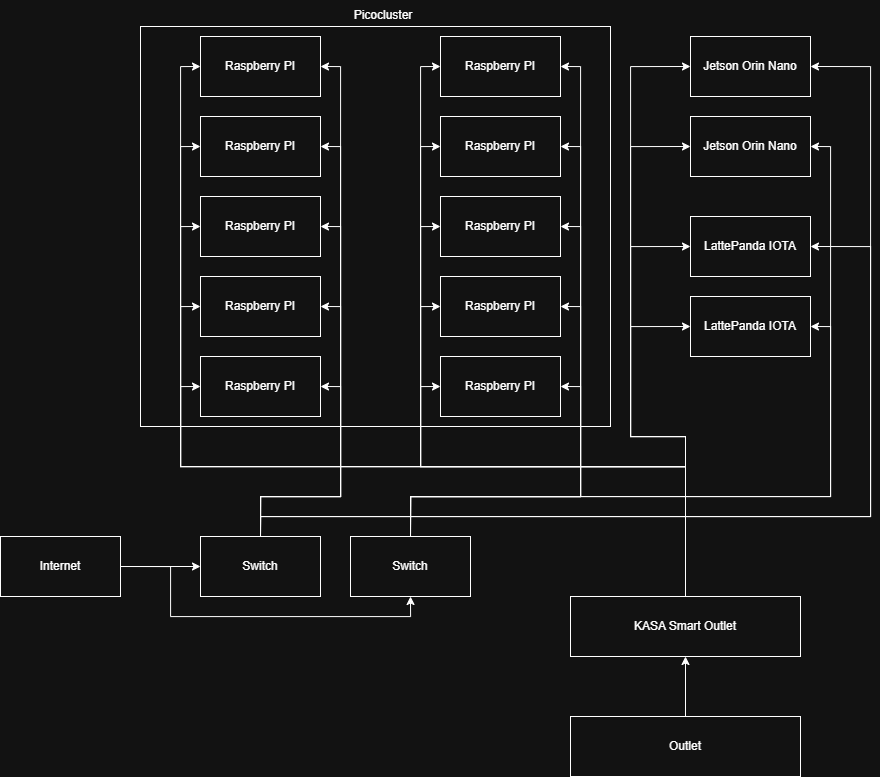
Hardware
We originally expected to recieve $6k in funding instead of having a $6k budget cap. Because of this, we had to scale back our original plans and use more of what we already had. Our Faculty advisor has a 10 RPi5-node picocluster worth $3k that we are using. This will be great for general worker nodes but we still needed some specialized boards for acceleration of the tasks. MDTest is dependent more on I/O speed which doesn’t benefit from the compute capabilities of the 10 RPis. The raspberry Pis only expose a single lane of PCIe 2.0, which is quite slow compared to today’s standards. To solve this, we needed something wth at least PCIe Gen3 x4. Thankfully, the Jetson Orins have this, so they can double as the GPU nodes and the fast storage nodes.
Power monitoring
We will be monitoring power by routing all consumption through a smart outlet.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| Raspberry Pi 5 (PicoCluster 10T) | 10 | CPU Compute | 120W (12W) | $3000 |
| Jetson Orin Nano | 1 | GPU Compute | 25W | $150 |
Software
We will be using Ubuntu on all our devices due to it’s familiarity and support. On top of that we will use Slurm scheduler to run the benchmarks on our cluster. For power monitoring, we will likely use a KASA python api, and create our own visualization.
Strategy
Benchmarks
We will begin by collecting as much data as possible, to gain some insight to model performance. Each team member will study the algorithms. Once better understood, we will find the best parameters for each of the benchmarks, and submit.
Applications
We will start by running the applications on a single node, then expanding to as far as we can. We will monitor network traffic, compute usage, and power usage, making sure each is optimal.
Team Details
Caleb - Robotics Engineering & Computer Engineering
Brock - Electrical Engineering
Indira - Computer Engineering & Applied Mathematics
Shiloh - Computer Science Game Design
Julien - Computer Engineering & Applied Mathematics
Jason - Computer Engineering
Holden - Robotics Engineering
Myles - Computer Science & Scientific Computing and Applied Mathematics
Team NTHU
National Tsing Hua University

Diagram
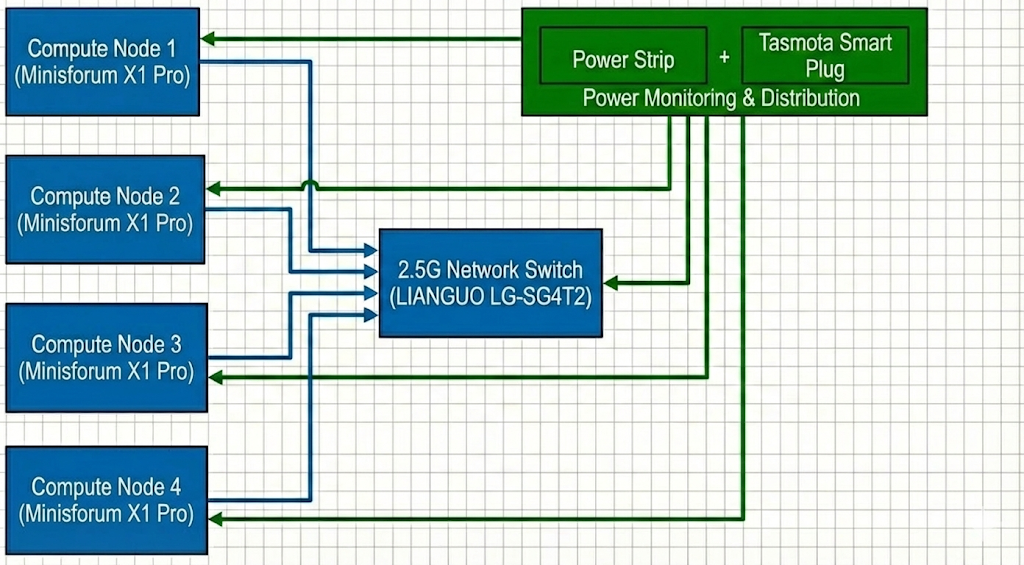
Hardware
For this competition, we will be using an AMD Mini PC cluster with 4 nodes. The Ryzen AI 9 HX 370 provides the latest Zen 5 architecture, which offers significant IPC improvements, crucial for high-performance numeric computing within a limited power envelope.
To strictly adhere to the 250W power limit, we will use cTDP (Configurable TDP) scaling to limit each node’s package power. Given the total budget, each node will be capped at approximately ~60W (depending on the switch’s overhead) to ensure the entire system remains stable under peak load.
Power monitoring
We will implement a real-time power monitoring system using Tasmota-flashed smartplugs. These plugs provide high-frequency power consumption data via their local API. We will deploy a Prometheus + Grafana stack to aggregate this data, providing the committee with a live, historical dashboard of the cluster’s total power draw.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| Minisforum X1 Pro Mini PC | 4 | Main nodes | 60~80W | $1350 per unit / $5400 in total |
| LIANGUO LG-SG4T2 | 1 | Network switch | 12W | $25 |
Software
Rationale: Our software stack is carefully selected to extract the maximum performance-per-watt from the heterogeneous Ryzen AI 9 APU. By maintaining a diverse suite of compilers (AOCC, LLVM, GCC, OneAPI), we can empirically determine the best AVX-512 vectorized binary for each specific workload. For distributed computing, we combine various MPI implementations with UCX and XPMEM to minimize latency over our 2.5G network and ensure high-speed intra-node communication. Finally, our comprehensive profiling toolchain (AMD uProf, rocprof, VTune) allows us to surgically identify and eliminate compute, memory, and power bottlenecks during the competition.
System & Compilers
- OS: Ubuntu 24.04 LTS
- FS: CephFS
- Intel OneAPI
- AOCC 5
- GNU 13
- LLVM
LIBs
- OpenBLAS
- AOCL-BLAS
Profile Tools
- VTune
- iPerf
- AMD uProf (For System & CPU profiling)
- rocprof (ROCm Profiler for GPU)
- AMD Radeon GPU Profiler
MPI & Communication
- IntelMPI
- OpenMPI
- MVAPICH4
- UCX
- XPMEM
Other
- Scheduler: HyperQueue
Strategy
Benchmarks
HPL
With the enabling of ROCm on newer Linux kernels, we will pivot from a CPU-only approach to an iGPU-accelerated HPL. By offloading GEMM operations to the 16 RDNA 3.5 CUs via hipBLAS, we expect a significant increase in performance-per-watt compared to pure AVX-512 execution. We will balance the cTDP to ensure the iGPU has enough thermal headroom to maintain high clock speeds.
Applications
D-LLAMA
Distributed-LLaMA (D-LLAMA) utilizes any device as a cluster machine and provides great AI capabilities. Given limited discrete GPU accelerators and fixed hardware constraints, we optimize the application mainly for CPU devices, ensuring the binaries fully exploit the underlying microarchitecture (such as AVX-512 and FMA instructions inherent to our AMD Ryzen environment) across the cluster. For more aggressive optimization, we are implementing a zero-copy networking backend. By bypassing the traditional kernel TCP/IP stack, we aim to reduce memory-to-network latency when exchanging tensor activations.
D-LLAMA is highly sensitive to parallel efficiency and communication overhead. To address this, we take a dynamic, topology-aware layer distribution strategy. Furthermore, adopting advanced quantization formats and enforcing strict CPU memory affinity (thread pinning) will significantly improve L2/L3 cache hit rates and KV-cache reuse during continuous inference runs.
MDTest
MDTest evaluates I/O metadata performance under intensive MPI communication; therefore, minimizing data transfer overhead between nodes is crucial. By enabling Jumbo Frames, network throughput is enhanced by packing more data per transmission, which effectively decreases packet processing overhead and relieves network congestion.
IQ-TREE
- Vectorization: We will use AVX-512 optimized builds of IQ-TREE to accelerate likelihood calculations, which is highly effective on the Zen 5 microarchitecture.
- Task Distribution: Utilizing HyperQueue to manage the massive number of tree-search tasks across the available threads in the cluster.
Mystery
Determine if the application is better suited for Vulkan-based or ROCm-based GPU acceleration or high-frequency CPU execution.
Team Details
| Name | Skills | Interests |
|---|---|---|
| Guan-Yu Ji | System Optimization | HomeLab |
| Jonathan Hsu | Profile | Motorcycle |
| Ke-Ying Chen | Parallel Programming | Trading |
| Chien-Lin Li | Distributed Optimization | Rhythm Games |
| Ming-Yang Zheng | Algorithm Optimization | Badminton |
Penguin Warriors
San Diego Super Computing Center / University of California, San Diego

Diagram
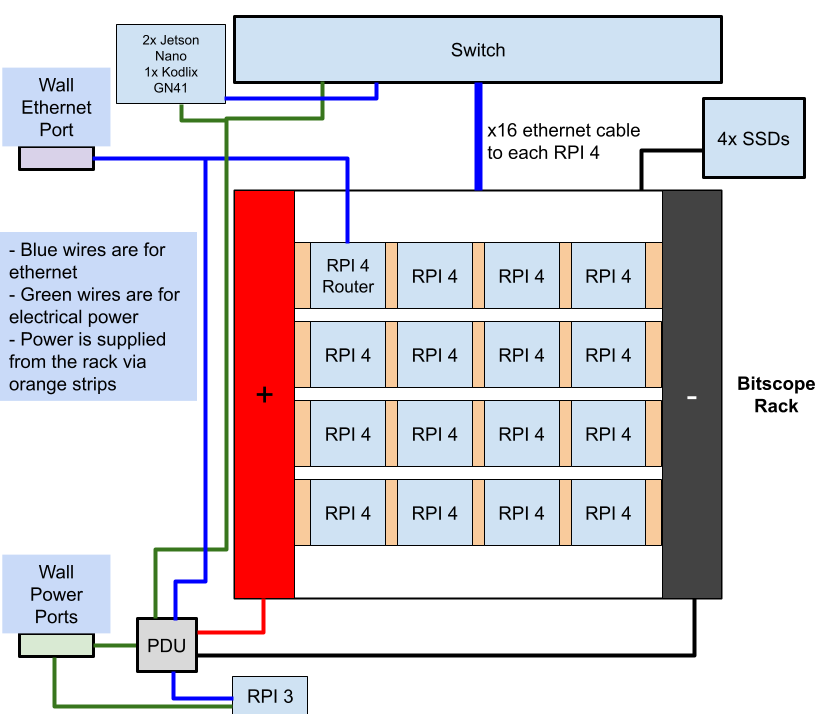
Hardware
We plan to use the Kodlix GN41 as a login node, which will also act as a router. This node is the only node that can be accessed through the internet. The rest of the nodes will be connected to a switch through Ethernet connections, and can be accessed through the login node via ssh. We are connecting 3/4 SSDs to each of the nodes.
Power monitoring
We plan to set up a Grafana display on our team website for the supervising committee to monitor. This Grafana display will be set up on the RPI 3, outside the power budget.
Hardware Table
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| Kodlix GN41 | 1 | Computing Equipment | 10W | $40 |
| Board from Yoga 9i | 1 | Computing Equipment | 20W | $205 |
| Board from Thinkbook 13x G1 | 1 | Computing Equipment | 15W | $150 |
| Board from Dell Precision 3490 | 1 | Computing Equipment | 20W | $800 |
| Board from Latitude 7420 | 1 | Computing Equipment | 10W | $150 |
| TP-Link 8 Port Gigabit Switch (TL-SG108E) | 1 | Switch | 10W | $25 |
| Intel SSD DC S4500 Series 240GB | 1 | Storage | 3W | $155 |
| Intel SSD DC S3520 Series 240GB | 1 | Storage | 3W | $189 |
| Intel SSD DC S3500 Series 300GB | 1 | Storage | 3W | $170 |
| Intel SSD D3-S4510 Series 240GB | 1 | Storage | 3W | $154 |
| USB Nic | 4 | Connection | N/A | $40 |
| Laptop Chargers | 4 | Supply power | N/A | $120 |
| Fan | 1 | Cooling | 5W | $20 |
| Short ethernet cable | 5 | Switch Connection | N/A | $8 |
| Long ethernet cable | 1 | Connection to outside internet | N/A | $10 |
| Power Strip | 1 | Outlet to the power supply and rack | N/A | $13 |
Software
We are using Debian 13 Trixie on all of our nodes. We used Ansible scripts to set up users and distribute ssh keys throughout the pi network to enable passwordless communication. Additionally, Ansible was used to install dependencies such as OpenMPI, G++, and OpenBLAS. We plan to install Slurm to schedule jobs and make sure we are using the cluster optimally.
Benchmark and Application Strategy
HPL
HPL will be compiled and run using OpenMPI and OpenBlas, with OpenBlas built to support efficient parallel execution. Our primary efforts will be towards systematically tuning HPL’s key parameters, N, NB, and process grid (P x Q), to maximize computational efficiency while minimizing communication overhead. Particularly, we will experiment with near P and Q configurations, test multiple NB block sizes to match cache and BLAS performance, and select N based on memory. We will monitor CPU utilization, memory usage, and communication bottlenecks to identify the highest-performing configurations for our cluster.
Dependencies: OpenMPI, OpenBLAS, C compiler
MD-Test
To improve MDTest performance, we will deploy BeeGFS to avoid centralized metadata bottlenecks. BeeGFS distributes metadata and storage across multiple nodes, enabling true parallel file operations. By using locally attached enterprise SSDs on nodes, we reduce latency and improve metadata throughput under concurrent workloads.
Dependencies: OpenMPI, C compiler, BeeGFS
D-LLAMA
We will test the 3.1 8B model extensively with various synchronization precisions and sequence lengths. We will also try running the model on all 16 pis or parallel run 2 batches of 8 pis.
Dependencies: Git, Python3
IQ-Tree
IQ-Tree will be optimized through MPI flags, compiler flags, and an understanding of the processes to figure out where bottlenecks occur. Monitoring CPU usage and RAM usage is anticipated to be important.
Dependencies: C++ Compilier, Boost, Eigen3, OpenMP
Team Details
Ryan Estanislao
Ryan Estanislao is a computer science student with experience in cybersecurity and benchmarking. He worked on ICON in the SCC24 home team and the STREAM memory benchmark and password decryption during SBCC25. As a travel team member for UCSD’s SCC25 team, he worked on the Exascale Climate Emulator. Additionally, he has worked on personal projects surrounding medical imaging and object detection in gaming.
Clover Li
Clover has experience with HPC through last year’s SBCC, played with Raspberry Pi 4s and benchmark STREAM, including figuring out that the firewall was the reason why STREAM wasn’t working. As an EE major, she is interested in system benchmarking and understanding how hardware and software choices affect application performance.
Aidan Jang
I am an Electrical Engineering major interested in parallel processing. I have a strong understanding of computer hardware and architecture. I’m excited to work on and optimise the D-LLAMA benchmarks!
Randy Bui
My name is Randy Bui, a fourth-year Math Computer Science major. I have prior experience in high performance computing through being on the SCC Home Team, having worked with MLPerf. I am also interested in understanding more how to make various applications run more efficiently. I’m also in the midst of improving my system administration skills.
Rahul Chandra
Rahul has prior experience in HPC through the SCC Hometeam (diagnosing HW issues and the reproducibility challenge) and an internship where he worked on benchmark design across hundreds of H100 nodes. Combined with the experience he’s gained in system administration and OS internals as a core maintainer of the Linux from Scratch book and his personal homelab, he is excited to get the most out of the hardware provided.
William Wu
William has prior experience in HPC through his participation in last year’s SBCC competition where he specialized in cracking passwords in parallel. William is interested in automating tasks and computing large amounts of data efficiently.
Angie David
Angie is new to HPC and is gearing her work towards supporting the setup of the D-Llama benchmark. As a 2nd year Electrical Engineering major, she’s expanding her software abilities to expand her scope beyond electronics.
Owen Cacal
Owen is new to working with HPC and software, but has been actively learning about Raspberry Pis. Although he is more interested in working with hardware, he wants to expand his interests and learn more about working with software, including HPL and MD-Test.
PlumJuice
Sapienza University of Rome

Diagram
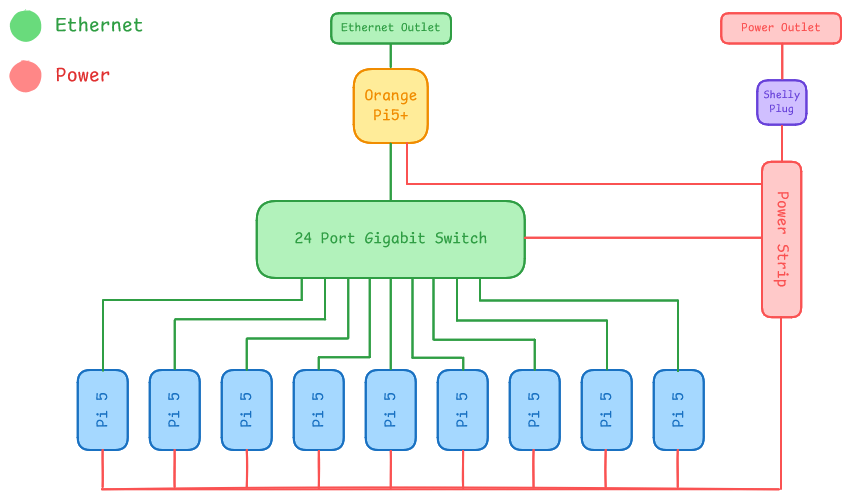
Hardware
Our hardware strategy focuses on maximizing compute density while maintaining a production-grade management layer.
-
Head Node and Management: For our head node, we utilize an Orange Pi 5+. This node acts as the cluster’s Internet Gateway, routing traffic between the external competition network and our internal subnet. It also functions as the Control Node, hosting the Slurm controller (slurmctld) and serving a centralized NFS share. This ensures that all worker nodes have a consistent environment for binaries and home directories, which is critical when using Spack for package management.
-
Compute Nodes: The compute fabric consists of nine Raspberry Pi 5 nodes.
-
Interconnect and Power: Networking is facilitated by a Tenda TEG1024D 24-port Gigabit switch, providing ample non-blocking bandwidth for internal cluster traffic. Power is centralized through a single power strip monitored by a Shelly Plug, allowing us to report live power metrics to the committee.
Hardware Table
| Item | Amount | Price (per unit) | Total Price | Expected Power Draw (per unit) | Cumulative Power Draw | Link |
|---|---|---|---|---|---|---|
| Raspberry Pi 5 (4GB) | 6 | 105 USD | 630 USD | 5-10 W | 30 - 60 W | https://tinyurl.com/kubii-raspi5-4gb |
| Raspberry Pi 5 (8GB) | 3 | 160 USD | 480 USD | 5-10 W | 15 - 30 W | https://tinyurl.com/kubii-raspi5 |
| Orange Pi 5 Plus (8GB) | 1 | 220 USD | 220 USD | 7-15 W | 7 - 15 W | https://tinyurl.com/orangepi-5plus |
| Cooling Fans for Raspberry Pi 5 | 9 | 7 USD | 63 USD | 1-3 W | 9 - 27 W | https://tinyurl.com/kubii-fan |
| Official Raspberry Pi 27W USB-C Power Supplies | 10 | 15 USD | 150 USD | 1 W | 10 W | https://tinyurl.com/kubii-power-supply |
| Tenda TEG1024D 24-Port Gigabit Ethernet | 1 | 75 USD | 75 USD | 15 W | 15 W | https://tinyurl.com/tenda-switch |
| Total | 1618 USD | 90 - 160 W |
Software
Our stack is designed to mirror an enterprise HPC environment, prioritizing reproducibility and performance:
-
Operating System: Rocky Linux (ARM64) is deployed across all nodes to provide a stable, RHEL-compatible base for scientific software.
-
Workload Management: Slurm is used for job scheduling and resource orchestration, ensuring optimal CPU affinity and task distribution.
-
Package Management: Spack is our primary tool for building the software stack. It allows us to compile optimized, architecture-specific versions of libraries like OpenBLAS and OpenMPI.
-
Environment Management: Lmod provides a clean hierarchical module system, allowing users to easily load and swap software environments for different benchmarks
Strategy
Benchmarks
-
HPL: Our strategy relies on utilizing Spack to build a highly tuned OpenBLAS library. We will focus on finding the optimal P×Q grid and block sizes while using Slurm to pin processes to physical cores, eliminating context-switching overhead.
-
MDTest: We will optimize the NFS configuration on the Orange Pi 5+ to minimize metadata latency. By tuning mount options and leveraging the head node’s dedicated CPU for I/O handling, we aim to sustain high file-operation rates across the cluster.
Applications
-
DLLAMA: We will utilize quantization (4-bit/8-bit) to manage the 4/8GB memory constraints of the Pi 5. Our goal is to balance model accuracy with inference speed by optimizing distributed tensor weights over our gigabit interconnect.
-
IQ-Tree: We will leverage the cluster’s 36-core fabric by distributing phylogenetic likelihood analyses through Slurm.
-
Mystery Application: Our Spack + NFS stack allows for “Build Once, Run Everywhere.” We can compile the mystery app on the head node and instantly deploy it to all workers, significantly reducing the “time-to-first-result.”
Team Details
Our team is supported by a senior group of Master’s students at Sapienza who bring a wealth of practical experience from international competitions. Having competed in IndySCC25 and currently preparing for ISC26, they serve as our technical advisors. This mentorship is helping us bridge the gap between theory and practice, particularly in fine-tuning our software stack and developing a solid workflow for competition-day troubleshooting.
-
Jacopo Mazzatorta (Team Lead) Jacopo is a 26-year-old student with a unique background in Economics, currently transitioning into Computer Science. His focus is on Systems Architecture and Parallel Programming. Within the team, he manages the high-level cluster orchestration and hardware optimization. He is particularly passionate about finding the most efficient way to scale software across powerful hardware clusters, and is also preparing to compete at IndySCC26.
-
Alessandro Milos Alessandro is a third-year Computer Science bachelor’s student with a strong interest in parallel programming and distributed systems. This is his first time participating in a cluster competition. He is particularly focused on understanding how interconnected systems coordinate and scale. Through this experience, he aims to deepen his knowledge of high-performance computing environments and communication protocols.
-
Jacopo Rallo Jacopo is a third-year Applied Computer Science and Artificial Intelligence student. He is currently exploring the fields of parallel programming and HPC, areas that have captured his growing interest. As a participant in IndySCC26, he aims to further sharpen his technical expertise and gain high-level hands-on experience in the field.
-
Pietro Piccolo Pietro is an ACSAI student at Sapienza University, specializing in the practical application of Artificial Intelligence to solve real-world problems. With a keen interest in software scalability and algorithmic efficiency, he bridges the gap between theoretical computer science user-centric technology.
RAMbo Clements
Clemson University / Coastal Carolina University

Diagram
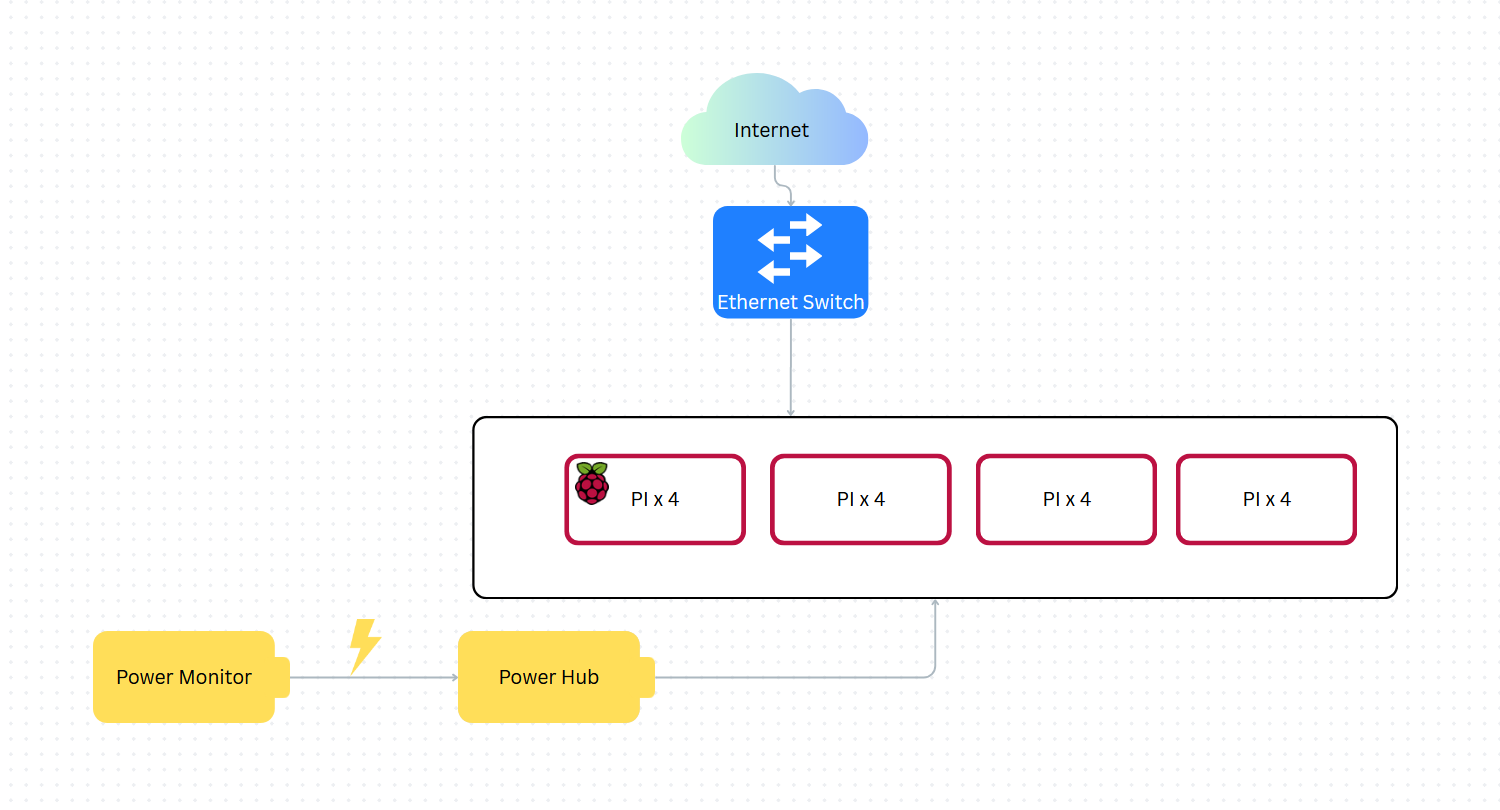
Hardware
We will use 16 Raspberry Pi 4B devices for our cluster setup. We don’t have additional funding for stronger hardware, but we plan to maximize the resources that we have available and demonstrate the potential gains of using cheaper hardware. There is a potential for adding an NVIDIA Jetson before the competition.
Power monitoring
Last year, we used livestreamed webcam footage of our cluster setup. We also reported our power draw with an energy-meter connected to the power supply for our cluster. We plan to follow a similar arrangement this year.
Hardware Table
Example:
| Item | Amount | Purpose | Expected Power Draw | Price |
|---|---|---|---|---|
| Raspberry Pi 4B | 16 | General applications | 160 W | $640 |
| NETGEAR 24-Port Gigabit Ethernet Unmanaged Switch (JGS524) | 1 | Connecting our cluster | n/a | $150 |
Software
Our software stack uses MPI to distribute the workload of our applications to CPU cores across our entire cluster, and Spack to install and manage packages in a way that runs quickly and efficiently by compiling many libraries without breaking dependencies. Since we don’t have a job manager, MPI CLI allows us to dynamically manage resource allocations. Using this, we can easily manage our resources and compute time. In HPC it’s essential for efficient, point-to-point and collective communication between processes. Spack’s non-destructive approach to compilation allows us to install packages into unique directories so that multiple versions can coexist, and its lack of a root requirement allows users to install software to their home environment, which makes it ideal for a shared HPC environment. Similarly, NSF allows us to access, view, and store files on remote network computers as if they were stored locally. It’s excellent for centralizing storage and improving scalability.
Strategy
Benchmarks
Our benchmark strategy will include setting up and testing HPL and MD-Test prior to the competition. For HPL, we will experiment with different numbers of nodes and HPL.dat settings prior to the competition and find the optimal parameters for performance. For MD-Test, we will test it on all nodes prior to the competition, identify potential bottlenecks that may reduce performance, and test various flags and parameters to find the optimal settings. Our goal is to have the benchmarks working and optimized by the time the competition starts, so we can spend more time on applications during the competition.
Applications
We will compile IQ-Tree from source and tune the application across different MPI ranks to improve our performance. We will also test a wide variety of the application’s uses so that we will be prepared for whatever tasks the competition may entail. For D-LLAMA, we will test the application on our cluster using a wide variety of models and benchmark inference performance so that we can have expectations for the resources necessary to complete the tasks for the application efficiently. We use Spack so that we can be quickly adaptable to the Mystery Application by being able to install and load new software into our environments efficiently.
Team Details
Jacob is a junior studying computer science and math. He’s worked on parallel algorithms for NASA GSFC and will join Google this summer to design low-level software for SmartNICs.
Nick is a freshman majoring in electrical & computer engineering and minoring in math. He has worked on robotics projects and is very interested in embedded computers.
Caleb is a junior studying Electrical and Computer Engineering. He’s worked on programs in C and is interested in coding as well as circuitry and their applications in embedded systems.
Adam is a junior studying computer science with a minor in ece. His primary interests are in HPC and computer vision.
Tolga is a sophomore studying computer engineering with a minor in mathematics. He’s interested in HPC and AI infrastructure and will work at Los Alamos National Lab this summer.
Anjali is a freshman studying Electrical and Computer Engineering. She is very interested in the application of HPC and its future applications.
CJ is a senior majoring in Computer Science and minoring in Applied Mathematics. He currently is a Student Research Assistant for Los Alamos National Laboratory through their contract with Coastal Carolina University specializing in using AI/ML for anomaly detection.
Ryon is a junior studying computer science and math. He does graphics-related GPU programming and his interests are in algorithms.
Team Kent Ridge
National University of Singapore

Diagram

Hardware
Our cluster comprises of ARM64-based compute nodes (Orange Pi 5 Max), with these key hardware specifications:
| Category | Specification |
|---|---|
| Master Chip | Rockchip RK3588 (8nm LP process) |
| CPU | 8-core 64-bit; 4× Cortex-A76 @ 2.4GHz + 4× Cortex-A55 @ 1.8GHz with independent NEON coprocessor |
| GPU | Integrated ARM Mali-G610; OpenGL ES 1.1/2.0/3.2, OpenCL 2.2, Vulkan 1.2 |
| NPU | 6 TOPS; supports INT4/INT8/INT16/FP16 hybrid computing |
| PMU | RK806-1 |
| RAM | 16 GB LPDDR5 |
| Storage | MicroSD card slot; M.2 M-Key (PCIe 3.0 ×4, NVMe SSD) |
| USB | 2× USB 3.0, 2× USB 2.0 |
| Ethernet | 1× 2.5 GbE LAN via PCIe (RTL8125BG) |
| Power Input | USB Type-C, 5V @ 5A |
| PCB Dimensions | 89 mm × 57 mm × 1.6 mm |
| Weight | 62 g |
| Power Consumption | 12.5W (expected) |
All SBCs will communicate over the NICGIGA 24-port switch and connect to each other via SSH.
Two Raspberry Pi 3Bs will be used (not included in the budget) for:
- a DHCP Server + DNS
- a Gateway / Firewall (required to access our university network, incoming connections disabled during the competition)
Power monitoring
The system will be connected to a Server Technology Sentry CW-8H2A413 Switched PDU for accurate power monitoring. The PDU will send power usage statistics to a Grafana dashboard, and a view of this will be shared live with the committee. The setup (including PDU) will also be livestreamed via video. We are happy to provide further verification of the power draw values.
Hardware Table
| Category | Item | Description | Quantity | Calculated Power Draw (W) | Cost per unit (USD) | Total Price (USD) |
|---|---|---|---|---|---|---|
| Compute | Orange Pi 5 Max 16GB | Single-Board Computer (SBC) | 17 | 210 | 249.00 | 4233.00 |
| Storage | Kioxia Exceria MicroSDHC U1 32GB | Operating System Drive | 17 | NA | 11.77 | 200.10 |
| Storage | Intel® Optane™ Memory M10 Series (16GB) | Metadata / Log Drive | 4 | 4 | 5.00 | 20.00 |
| Storage | Crucial T500 PCIe Gen4x4 NVMe M.2 SSD (1TB) | NFS Drive (Fast) | 2 | 3 | 167.31 | 334.62 |
| Storage | Crucial P310 PCIe Gen4x4 NVMe M.2 SSD (1TB) | NFS Drive (Cheap) | 1 | 1.5 | 164.00 | 164.00 |
| Network | NICGIGA 24-Port 2.5G Ethernet Switch (S25-2400) | Network Switch | 1 | 15 | 249.99 | 249.99 |
| Power | DC5.5 x 2.1mm Female Jack to USB Type-C | Power Adapter | 17 | NA | 3.08 | 52.50 |
| Power | DC Power Fuse Distribution Strip | Power Distribution | 2 | NA | 48.30 | 96.60 |
| Power | Meanwell LRS-300-5V w UK Plug | Power source | 1 | NA | 36.34 | 36.34 |
| Power | 14AWG 100ft Electrical Wire | Power Cable | 2 | NA | 15.00 | 30.00 |
| Network | Cat5E + Cat6 Cables (Various Lengths) | Network Cables | 17 | NA | 1.56 | 26.56 |
| Cooling | ARCTIC P14 Pro PST | Fans | 3 | 12 | 9.00 | 27.00 |
| Cooling | 14x14x6mm and 22x22x10mm Heatsinks | Heatsinks | 17 | NA | 0.56 | 9.61 |
| Casing | DIY 10“ Server Rack (2020 Extrusion) | Server Rack | 1 | NA | 204.02 | 204.02 |
| Power | DC5.5 x 2.1mm Male Jack | Power Adapter | 17 | NA | 0.28 | 4.83 |
| Totals | 242.5 | 5689.17 |
Software
- Operating System
- Armbian Linux: Best support for Orange Pi
- Cluster Orchestration and Management
- Ansible: Orchestration tool, eliminating the need to manually set up individual SBCs
- SLURM: Job scheduler and workload manager. Chosen for team familiarity due to being used in university’s cluster.
- Grafana: Dashboard for system monitoring. Chosen for team familiarity.
- Prometheus: Used to collect and store real-time metrics such as power usage and temperature.
- Storage
- BeeGFS: Parallel file system for higher IO throughput.
- MPI
- OpenMPI: For multi-node runs,
- Linear Algebra Libraries
- OpenBLAS: Linear algebra operations.
Strategy
Benchmarks / Applications
- High Performance Linpack (HPL)
- HPL is installed and compiled with OpenBLAS.
- We will experiment with several parameters (such as problem size
Nand block sizeNB) and tune them for our system. - Tune to maximize TFLOPS.
- D-LLAMA
- Compiled from source following the official repository documentation.
- Implementation of weight quantization and exploration of NPU-offloaded computation.
- MDTest
- Compiled from the MDTest source utilizing OpenMPI.
- Test different storage methods like BeeGFS.
- Optimise with MPI rank placement and network tuning.
- IQ-TREE
- Compiled from source.
- Tune with OpenMP and MPI for ranks and threads per node.
- Mystery Application
- Assign team members based on the mystery application and members’ individual interests.
Team Details
| Name | Interests! | Responsibilities |
|---|---|---|
| Muhammad Asyraf Bin Abdul Rahim | Motorsport / tinkering / gaming | Hardware and system design & management, Ansible system admin |
| Lau Zhe Wen | Photography | Hardware procurement, optimizing IQ-TREE and SLURM |
| Tan Yong Xiang | Likes climbing things | Hardware procurement, power system design, optimizing IQ-TREE |
| Mande Neil Ashvinikumar | Networking (the ethernet kind) enthusiast | Network setup, optimising MDTest and BeeGFS |
| Gabra Shubhan | Playing chess, playing cricket, travelling | Hardware procurement, power system design, optimizing D-LLAMA |
| Chan Dong Jun | Stargazing | Ansible system admin, optimizing D-LLAMA and general software |
| Joel Chong | Low latency systems, C++ enthusiast (very enthusiastic) | Optimizing HPL, kernel, network and general software |
| Koh Tze Rui | Also likes climbing things | Hardware procurement, optimizing HPL |
Tech Titans
University of Botswana

Diagram
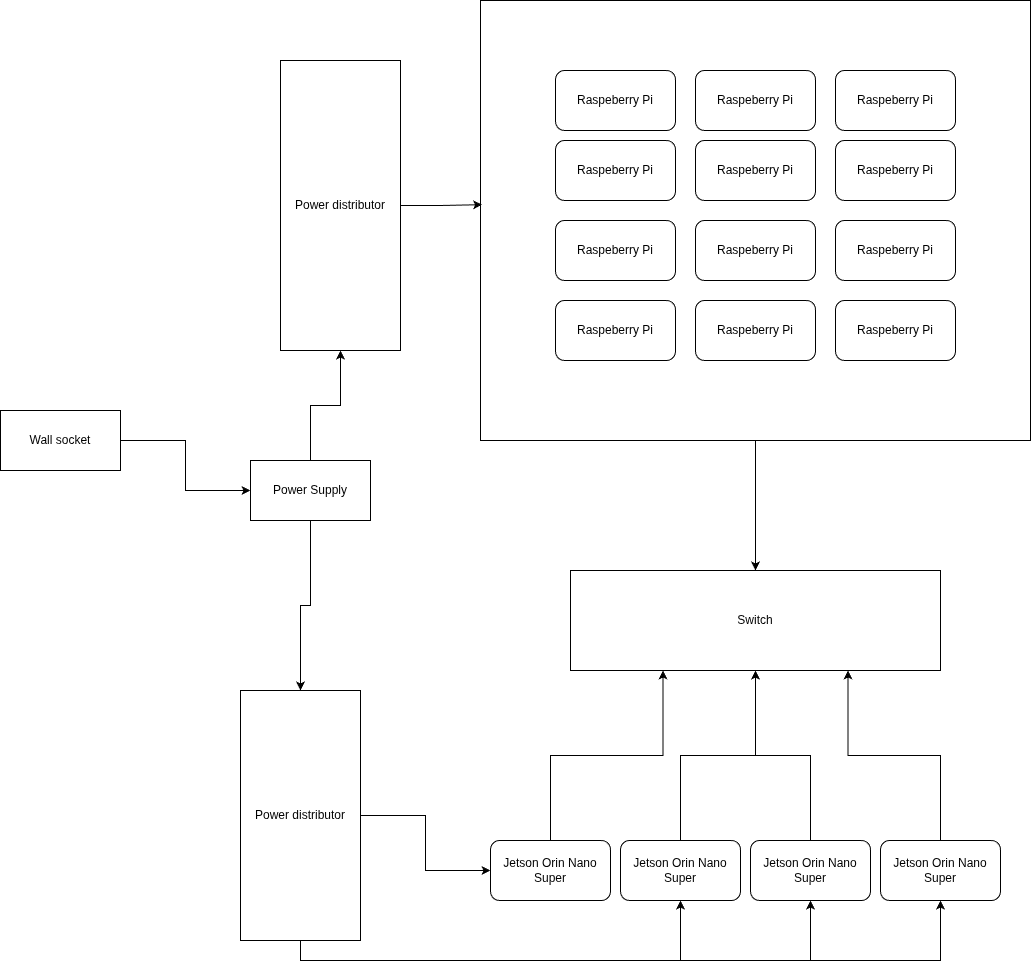
Hardware
Nvidia Jetson Orin Nano Super and Raspberry Pi 5(8gb) - A mixed setup to get best of both worlds. HPL benchmark we can get better GFLOPs from using GPU acceleration over using CPU, D-LLAMA using the GPU is better because the are tensor cores that give a better outcome and MD-TEST due to Jetson Orin Nano Super accepting NVME which gives better performance for the benchmark as well as reducing the bottleneck. Since IQ-tree requires cores we have the Raspberry Pi’s to do this benchmark
Power monitoring
To track the total 250W limit for the entire setup (including the switch and fans), we install a professional-grade energy meter like the Shelly Pro 3EM at the main power input. We will then run a Shelly Prometheus Exporter on our head node, which queries the Shelly API to pull aggregate metrics like shelly_total_power_watts into our time-series database.
Finally we configure a central Grafana Dashboard to unify these data sources. This allows us to create a “Live Power Meter” gauge that turns red as you approach 240W, while simultaneously graphing “Watts per GFLOPS” to prove the efficiency of our heterogeneous architecture to the committee.
Hardware Table
| Item | Amount | Expected Power Draw | Price Per Unit |
|---|---|---|---|
| Raspberry Pi 5 (8gb) | 12 | 144W | 136 |
| Nvidia: Jetson Orin Nano Super | 4 | 80W | 249 |
| SanDisk Extreme 128GB MicroSD | 12 | 40 | |
| Samsung 970 EVO Plus SSD 500GB | 4 | 140 | |
| TP-Link 24-Port Gigabit Ethernet Unmanaged Switch | 1 | 13.1 | 90 |
| Shelly Pro 3EM 3CT 63 | 1 | 100 | |
| DC Power Fuse Distribution Strip Module (6 Position, DIN Rail Mount) | 1 | 28 | |
| DC Power Fuse Distribution Strip Module (12 Position, DIN Rail Mount) | 1 | 38 | |
| Rapink Patch Cables Cat6 | 2 | 21 | |
| Electrical Wire 14 AWG 14 Gauge Silicone Wire Hook | 16 | 10 | |
| USB C to 2 Pin Bare Wire Open End Power Cable | 12 | 10 | |
| GeeekPi Cluster Case for Raspberry Pi - Stackable 12-Layer Rack With Cooling Fan | 2 | 5W | 83 |
| Fancasee 16AWG DC Power Pigtail Cable, 5.5mm x 2.5mm DC Barrel Male Plug | 4 | 7 | |
| Total | 4350 |
Software
OS: Ubuntu 24.04 LTS (Pi) and JetPack 6.2 (NVIDIA).
Orchestration: Slurm for job scheduling and resource allocation. Ansible to automate the management of all nodes
Containerization: Singularity/Apptainer to ensure benchmark reproducibility across different ARM architectures.
Implementation: cuBlas because I want to utilise the GPU. MPCHI for its predictability in arm architecture
Rationale: Slurm allows us to define “partitions” so that D-LLAMA jobs are automatically routed to the NVIDIA nodes while IQ-TREE scales across the Pi worker nodes.
Strategy
Benchmarks
- HPL: We will use the CUDA-accelerated HPL on the Jetson nodes. By offloading matrix decomposition to the 4,096 CUDA cores, we expect to achieve GFLOPS results that a CPU-only Pi cluster cannot reach.
- No D-LLAMA: Our strategy involves distributed inference using llama.cpp with the RPC backend. The Jetsons will serve as the primary compute engines (using Tensor cores), while the Pis manage context and orchestrate the request stream.
Applications
- MDTest: We will run this specifically on the NVIDIA Tier using the NVMe SSDs. Testing metadata performance on SD cards is a bottleneck; using the MB/s throughput of the NVMe drives will maximize our IOPS score.
- IQ-TREE: We will utilize the 12-node Raspberry Pi tier. Since IQ-TREE is highly parallel and CPU-bound, we will launch multiple instances across the 48 available Pi cores to find the maximum likelihood trees in parallel.
Team Details
Theo Kgosiemang - Fourth year computer science student interested in all things software engineering.
Jonathan Mosoma - Second year computing with finance student Interested in HPC and performance engineering.
Pholoso Lekagane- Fourth Year Computer Science undergrad looking to expand their skill set
Chandapiwa Malema:Fourth year computer student with an interest in HPC
Mehedi Hasan Mahin- Third year computer science student and interested in Artificial Intelligence.
Ray Mcmillan Gumbo- Third year computer science student with an interest in Artificial Intelligence
Those Who Node
San Diego Super Computing Center / University of California, San Diego

Diagram
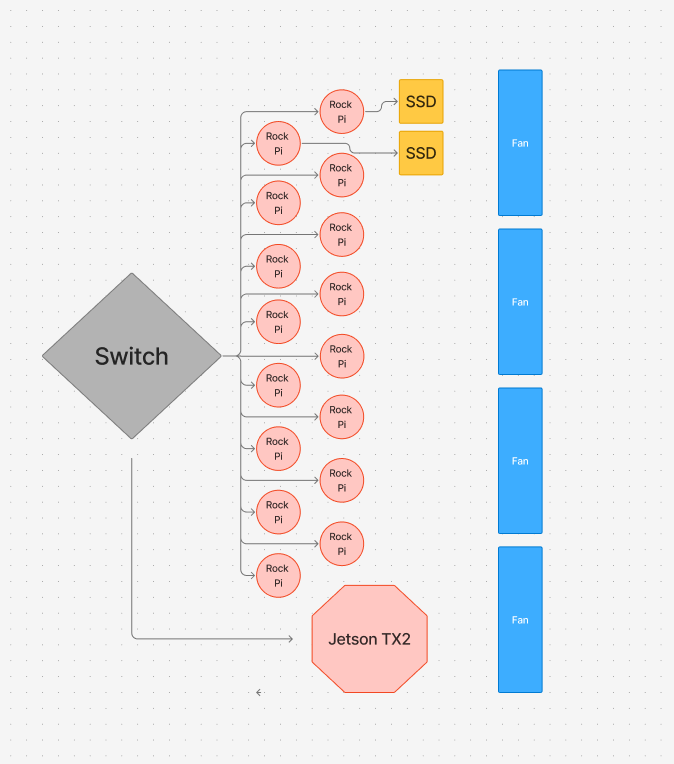
Hardware:
- For our cluster, we use 15 Rock Pi 5Bs
- They are connected to our switch via a cat6 ethernet cable
- We power the Rock Pis via USB-C power cables
- 2x MV-V7E500 500GB SSDs (1 TB total)
- 1 SSD will be on the login node, while the other will be on a different node (we may call this the secondary login node)
- Jetson TX2
Power monitoring
During the early stages, we will set up node_exporter on all the nodes in our cluster to export power draw estimates, and use Prometheus and Grafana to collect and visualize the data. We will eventually use a queryable metered PDU to measure our cluster’s exact power draw, including the switch and peripherals.
Hardware Table/Bill of Materials
| Part | Units | Wattage/Unit | Cost per unit | Total Price |
|---|---|---|---|---|
| RADXA Rock Pi 5B (16 Gb RAM) | 16 | 12 | 199.90 | $3198.4 |
| Unifi Switch 48 | 1 | 40 | $399.00 | $399.00 |
| MV-V7E500 500GB SSD | 2 | $79.00 | $158.00 | |
| Enclosure (DIY) | 1 | 0 | $79.92 | $79.92 |
| Fan | 4 | 1.56 | 7.90 | $31.6 |
| Jetson TX2 | 1 | 10W | $549.00 | $549.00 |
| TOTAL COST | $4415.92 |
Software:
Our software stack is as follows:
- Operating System: Our system runs Armbian 25.11.1, as it is a lightweight linux distribution that is optimized for ARM hardware.
- Cluster Management: We manage the machine state, including creating users, managing shared files, and installing packages using multiple ansible scripts for simplicity and cluster reproducibility.
- Operational Security: We disable root login and password-based authentication, and use key-based access control for all users across the cluster.
- Users access the cluster via a login node with the hostname rock0
- Container Runtime: Docker is installed on cluster nodes to support nodes to support containerized tools
- GPU Runtime Support: We provision Vulkan packages and ICD config so GPU intensive tasks can be tested consistently
- Job Scheduling: We will use Slurm for job scheduling, allowing us to manage and run jobs even when away from the cluster.
- Package Management: We manage dependencies across the Pis using Spack, allowing us to easily load modules when required for a task.
- Filesystem Management: We have shared directories across the Pis, allowing for convenient access to modules and apps in a uniform location across the cluster. The shared directories are mounted using NFS.
- Communication: To run applications across the cluster, we use Open MPI 4.1.6.
- Compiler: We use the GCC compiler for compiling.
- Application and Benchmark Dependencies:
- HPL: OpenBLAS 0.3.30 and OpenMPI 4.1.6
- IQ Tree: Eigen 3.4.0, OpenMPI 4.1.6, and GCC 14.2.0
- Dllama: GCC 14.2.0 and Python 3.13.5
- MDTest: GCC 14.2.0 and OpenMPI 4.1.6
Strategy:
Benchmarks
HPL:
- We will use spack to easily load in and manage modules across the cluster. We will use Open MPI and OpenBLAS to compile and run HPL, with OpenBLAS compiled specifically for parallelized MPI environments. The bulk of our focus will be on tuning HPL parameters for maximum performance on our cluster - we intend to try multiple strategies for this, including brute force searches and Bayesian optimization.
MDTest:
- For MDTest, I plan on focusing on how different MPI binding and mapping configurations affect the run time of MDTest, as well as measuring the speed and time of running MDTest through a shared NFS directory or through separate local directories, and tune my MDTest run settings accordingly to achieve maximum speed and minimize variation. I also intend to identify important bottleneck points in metadata, as well as limits in per node storage.
D-LLAMA:
- For D-LLAMA, we first profile the full inference run to find the main bottleneck (compute, memory, sync, or network). Then we apply simple high-impact fixes like cleaning up setup, removing extra copies, improving scheduling, and cutting unnecessary synchronization. After the baseline is stable and faster, we add Rock Pi accelerators (GPU and NPU where it makes sense) to offload the most expensive work. If we still have time, we try pipeline parallelism or a tensor–pipeline hybrid to reduce communication and scale better across nodes.
Applications
IQTree:
- For IQ-TREE, we first study the application itself, what biological problem it solves, how it consumes multiple sequence alignment data, and where the heavy computation actually happens in the likelihood search. Then we profile a full run to identify the dominant bottleneck: pure compute, memory pressure, or MPI communication overhead. Once we understand the baseline behavior, we apply high-impact optimizations: compiling specifically for ARM to maximize floating-point performance, ensuring efficient MPI configuration, reducing unnecessary data movement, and staging input locally to avoid I/O bottlenecks. After stabilizing single-node performance, we benchmark strong scaling across nodes to measure parallel efficiency and identify when communication begins to limit gains. If scaling drops, we focus on improving load balance, adjusting process placement, and tuning MPI parameters to reduce synchronization and network overhead. Throughout, we validate changes with repeated, controlled benchmarks on fixed alignment datasets so every improvement is measurable and justified.
Mystery Application:
- For the mystery application, we will ensure that all of our team members have a solid understanding of our system, comfort with HPC concepts, and an understanding of commonly used tools so that we can work quickly once the application is revealed. We also plan on reviewing documentation from previous UCSD teams to better understand how the mystery application can be conducted and optimized.
Team Details:
Cecilia Li
- My name is Cecilia Li. I’m a second-year Electrical Engineering student. I competed in SBCC 25 and SCC 25. I am interested in digital IC, ASIC design, and ML sys. I am working on HPL and IQ-Tree.
Tom Lu
- My name is Tom Lu, a second year Computer Science major at UCSD. I participated in SC25 as a home team member, and this is my first time participating in SBCC. I’m interested in Computer Architecture, Hardware-Software Co-Design, and Parallel Computing.
Chanyoung Park
- My name is Chanyoung Park, and I’m a third-year Data Science student at UC San Diego. I competed in SBCC 2025 as a team member and participated in SCC 2025 as an alternate. I’m especially interested in hardware acceleration, machine learning systems and architecture, and performance optimization.
Chetan Thotti
- My name is Chetan Thotti, and I’m a first-year Computer Science major at UC San Diego. This is my first time competing in SBCC or any related competitions, so I don’t have prior experience. I became interested in high-performance computing because of how rapidly the world’s data usage is growing, and I’m curious about the ways we process and manipulate large-scale data across different applications. I’m specifically working on tuning HPL and optimizing D-LLAMA.
Ibrahim Altuwaijri
- My name Is Ibrahim Altuwaijri, I’m a third year Computer Engineering major at UCSD. I’m interested in computer architecture and distributed systems. I have some experience with running software using MPI. And designing IoT devices.
Yixuan Li
- My name is Yixuan Li, and I’m a second-year Computer Science Major at UCSD. I competed in SBCC 25 as UCSD Team 2’s sysadmin, and I also participated in SCC 2025 as an alternate. I’m mainly working on system setup, administration, and networking.
Aidan Tjon
- My name is Aidan Tjon, and I’m a first year student at UC San Diego studying Artificial Intelligence. I participated in SCC 2025 as a home team member. I’m interested in high performance computing, specifically building reproducible environments on Linux, working with clusters and schedulers like Slurm, and tuning workloads so they actually run fast and reliably.
Yuting Duan
- My name is Yuting Duan, and I’m a third-year Computer Science transfer student at UC San Diego. This is my first time participating in SBCC. I’m interested in high-performance computing and how computational power can be used to build software that supports scientific research and simulation.
Schedule - based off any given teams local time
Unless explicitly mentioned, the start and end timings refer to the timezone for which your team has signed up for.
April 9, 2026 (Thursday): Setup day
Most of the setup day can be “disregarded” except for camera and video stream of a power meter. Teams are welcome to take apart their cluster and rebuild it on this day for extra practice.
| Start time/date | End time/Date | Details |
|---|---|---|
| 8:00 am | 8:00 am (the next day) | Competition Teams set up and run preliminary tests. Please have a 2 video feeds. One of your live power monitor, and another of your cluster. It is okay to receive help from your team advisor at this point. |
April 10, 2026 (Friday): Competition Day 1
| Start time/date | End time/Date | Details |
|---|---|---|
| 8:00 am PDT | 8:30 am PDT | Opening Ceremony |
| 8:00 am | 1:00 pm | Teams will complete their official benchmark (HPL, MDTest, and DLLAMA) runs and submit them. |
| 12:00 pm (noon) | 5:00 pm | Mystery Application is revealed at 12:00 pm. Teams will complete the applications (IQ Tree and Mystery) and submit them. |
| 5:00 pm | 8:00 am (the next day) | Teams must leave the cluster running, unattended, and inaccessible. A job scheduler is allowed. |
April 11, 2026 (Saturday): Final Competition Day
| Start time/date | End time/Date | Details |
|---|---|---|
| 8:00 am | 3:00 pm | Teams will continue to complete the applications (IQ Tree and Mystery) and submit them. |
| 3:00 pm | 5:00 pm | Committee grades submissions. Teams are encouraged to take a break. |
| 5:00 pm PDT | 6:00 pm PDT | The final results are announced. |
Note: Final results announcements are done with respect to Pacific Standard Time.
Setup
The complete duration of Thursday is for setting up your clusters.
You can speak to any outside sources and real people about the cluster and help up until 8am Friday. You are always open to speak to other teams.
General instructions
Please put a video on display of your overall setup and a view of your power monitor. You will be trusted that you will not be accessing your cluster remotely, but leave the cameras on if you can. Camera setups are expected to be unique. Please work with the committee to set up a suitable camera setup before the end of setup day.
Application Announcements
For announcement of application specifications according to the calendar based on your local time zone. Please coordinate with competition organizers.
Networking
The main network constraint is having one exit point to the internet. And that the internet is unable to initiate connections into any of your servers. A computer that is solely running DHCP (or some sort of networking that solely assigns IPs) can be excluded from your power budget.
A central switch that has a DHCP, for example, would count. However, a router running DHCP connected to a central switch would not count.
Power
For power, since you are remote, we expect you to have a log (aka your video recording) of your power and during submissions, include a full log of your cluster’s power consumption throughout the competition.
Access
Teams are required to access their cluster using physical Ethernet cables during the benchmarking and application periods (no wireless connections). Teams may not access their clusters after 5:00pm local time, and are suggested to use a job scheduler for overnight runs.
HPL
HPL should be run with 4 nodes at a minimum. Any publically acessible and TOP500/Green500 compliant implementation of HPL is allowed. HPL will be graded on Flops per Watt. The wattage will be the peak power used during the run.
Please upload a copy of your .dat files and the output file produced.
- Submit your *.dat file used for your submission run
- Submit your output, usually called HPL.out by default if
fileis your output specified in your*.datinput.
We will also be asking for compressed files assembled from your logs, such as /var/ from login nodes/main nodes. Time stamps in PDT for the start and end times for your run are also requested.
Do not submit files twice
DLLAMA
Source code: https://github.com/b4rtaz/distributed-llama
General Guidelines
For each task, teams will run a short, long, and leadboard prompt and report the tokens/s throughput (exact guidelines will be sent out once determined). The performance on short and long prompts will be evaluated internally, while the performance on the leaderboard prompt will be evaluated in comparison to the leaderboard consisting of all the teams that submit. If you have any questions, please ask in the Q&A section of the competition Discord!
Task 1: Llama 3.1 8B Instruct Q40 (base model)
Teams will benchmark the Llama 3.1 8B Instruct Q40 model on provided prompts using the dllama inference mode, with 3 worker nodes (4 nodes total), 2 threads per node and a maximum sequence length of 4096. For this task, teams must use the Llama 3.1 8B Instruct Q40 model and tokenizer provided in the Distributed Llama repository with no changes to the source code. The results from this task will also serve as a baseline for Task 3.
Task 2: Qwen 3 8B Q40 (base model)
Teams will benchmark the Qwen 3 8B Q40 model on provided prompts using the dllama inference mode, with 3 worker nodes (4 nodes total). For this task, teams must use the Qwen 3 8B Q40 model and tokenizer provided in the Distributed Llama repository with no changes to the source code; however, teams are allowed to change thread count, maximum sequence length, and other runtime parameters as long as the model, tokenizer, and source code remain unchanged.
Task 3: Llama 3.1 8B Instruct Q40 (optimized)
Teams will benchmark the Llama 3.1 8B Instruct Q40 model on provided prompts. For this task, teams are encouraged to explore possible optimization (such as modifications to the DLLAMA source code, alternative inference engines, or software/hardware advantages). Model throughput in this task will be evaluated in comparison to the teams’ results in Task 1. For the leaderboard results, multinode runs are preferred and will be weighted accordingly.
Teams will be required to submit code for this task (ex. a fork of the source code repository) with well-documented changes and explanations of the optimizations made. The teams’ effort and approach to optimization will be taken into account during scoring. Code submissions must be made before benchmarking begins (detailed guidance to come).
Competition Instructions
Here is the full document: https://single-board-cluster-competition.github.io/sbcc26-competition-site/files/SBCC26_D-LLAMA_Instructions.pdf
MDTest
https://wiki.lustre.org/MDTest
Instructions: https://single-board-cluster-competition.github.io/sbcc26-competition-site/files/MDTest_Rules_SBCC_2026.pdf
Capture all relevant files/output and submit them.
IQ-TREE
IQ-TREE is a bioinformatics software tool used to reconstruct phylogenetic trees from molecular sequence data such as DNA, RNA, or proteins.
Phylogenetic trees are diagrams used to represent the evolutionary relationships among different organisms or genes, showing how they evolved from common ancestors over time. To build these trees, scientists align DNA, RNA, or protein sequences from the species of interest. This alignment allows researchers to identify patterns of similarity and difference that reflect evolutionary changes.
Given an alignment file, IQ-TREE searches for the tree topology that most likely explains the observed sequence alignment under a given evolutionary model. The software supports a wide range of complex evolutionary models, including partitioned datasets and mixture models, making it suitable for both small and large-scale phylogenomic analyses. Because of its speed, scalability, and built-in statistical tools, IQ-TREE has become a popular choice for researchers studying evolutionary relationships across diverse biological datasets.
Source code: https://github.com/iqtree/iqtree2
Guidelines
Teams will be provided with a set of datasets and tasks at the beginning of the application period. Please refer to the IQ-TREE documentation, including the beginner tutorial and the advanced tutoral for examples of possible tasks. Teams are expected to use IQ-TREE version 2.4.0. Any modifications to the source code must be disclosed to and approved by the committee by April 3rd.
We are also planning an interview component where teams will be able to demonstrate their understanding of the IQ-TREE software. In the week before the competition, the committee will reach out to schedule a short interview that will occur while the teams are completing application tasks.
Competition Instructions
Here is the full document: https://single-board-cluster-competition.github.io/sbcc26-competition-site/files/SBCC26_IQ-TREE_Instructions.pdf
Mystery App
The mystery application for this year is ICON! ICON is a high performance climate prediction, weather forecasting, and environmental emulation application framework.
Read more about this application here!
Competition Instructions
Here is the full document: https://single-board-cluster-competition.github.io/sbcc26-competition-site/files/Mystery_APP.pdf
Systems Overview
The systems interview was added as another part of the competition.
Some topics that may be asked will be
- design decisions (including operating systems)
- infrastructure (including power usage)
- management and security
- other details that have gone into building and maintaining your system
Additionally, talking about the problems encountered along the way can be very telling of the effort behind the cluster.
Interviews will be around 10-15 minutes.
Log Submission
Compress the paths where logs are often stored, usually just /var, from the head/login/main compute nodes. If your team believes that the logs after a certain number of nodes are too similar, exclude them. This means if you feel that node 1, node 2, and node 3 have the most distinct logs, but the following nodes 4—12 nodes are just a repetition of the first 3 logs, just exclude them. We will ask for these files to be submitted at the end of the competition.
Create a folder called Logs/ in your google drive and place them there.
Make sure to send a picture of your team with the cluster to the committee as well. This can be a possible location to put it.
The log submission does not receive points, but is required to have some record of the clusters.
Grading Breakdown
Depending on time zones forward of Pacific Coast Time many of you will be either substantially into your setup day or just ahead of us. We would like to accept submissions for the benchmarks (should all be single text files) into the competition’s google-drive location, but we will only allow access each team’s submission folder to members of that team.
The overall score for any individual team will be measured as follows with individual application scores being weighted against the team who scores the highest for that given application, i.e. if the highest benchmark result for HPL is 160 GFLOP/s the scores for every other team will be 10*(their score)/ (160 GFLOP/s).
| Application | Weight | Normalised |
|---|---|---|
| HPL | 10.8% | x |
| MDTest | 10.8% | |
| DLLAMA | 16.2% | |
| IQ Tree | 26.1% | |
| Mystery App | 26.1% | |
| Systems | 10% | |
| Total | 100% | x |
🏆 SBCC26 Final Results
Below are the top 3 teams in each category:
🔢 HPL (High Performance Linpack)
- 🥇 NTHU
- 🥈 Team Kent Ridge
- 🥉 Plum Juice
🦙 DLLAMA
- 🥇 Team Kent Ridge
- 🥈 Penguin Warriors
- 🥉 Those Who Node
📁 MDTest
- 🥇 Team Kent Ridge
- 🥈 Those Who Node
- 🥉 GigaDawgs
🌲 IQ Tree
- 🥇 Penguin Warriors
- 🥈 Those Who Node
- 🥉 GigaDawgs
❓ Mystery (ICON)
- 🥇 Crossroads Coders
- 🥈 Penguin Warriors
- 🥉 Team Kent Ridge
🖥️ Systems
- 🥇 Team Kent Ridge | Penguin Warriors | NTHU
- 🥈 GigaDawgs
- 🥈 Those Who Node
🏁 Overall Standings
- 🥇 Team Kent Ridge
- 🥈 Penguin Warriors
- 🥉 Those Who Node
Organizers
Current Competition Organizers
- Abir Haque
- Jackson Yang
- Gauri Renjith
- Ferrari Guan
Previous Competition Organizers
We would like to thank all the previous competition organizers for their contributions to this competition.
- Francisco Fabian “Paco” Gutierrez Lopez
- Khai Vu
- Ritoban Kumar Roy-Chowdhury
- Benjamin Li
- Casper Nyvang Sørensen
- Zixian Wang
- Shijie “Jacob” Wang
- Zhiheng “Henry” Feng
- Christian Ziegler “S3JER” Sejersen