Texas Tech University - Team RedRaider
Diagram
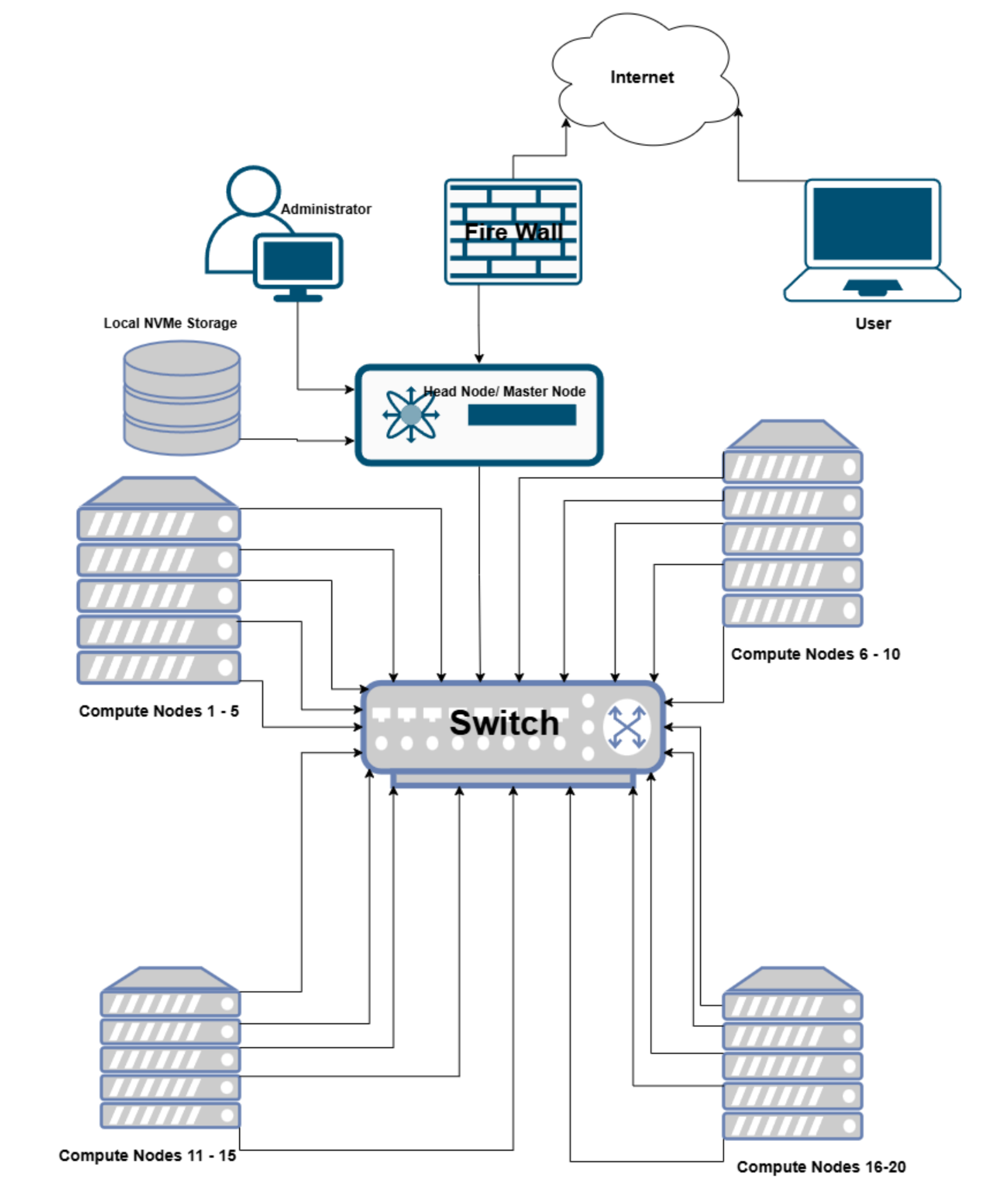
Hardware
| Item name | Cost per item | Number of items | Total item cost | Link or Description of the item |
|---|---|---|---|---|
| Radxa SLiM X4L board | $178.86 | 1 | $178.86 | Radxa SLiM X4L board |
| Radxa X4 boards | $21.56 | 20 | $431.20 | Radxa X4 boards |
| Ethernet Switch | $64.95 | 1 | $64.95 | Ethernet Switch |
| Power supply | $13.90 | 22 | $305.80 | Power supply |
| Ethernet cables | $10.00 | 22 | $220.00 | Ethernet cables |
| Power meter | $65.99 | 1 | $65.99 | Power meter |
| Case Fan | $9.00 | 1 | $9.00 | Case Fan |
| Heat sink | $19.95 | 1 | $19.95 | Heat sink |
| GeekPi 8U Server Rack with 4 extra shelves and blanking panels | $299.91 | 1 | $299.91 | GeekPi 8U Server Rack, Extra shelves, Blanking panels |
| Fan Grill 1400mm Guard Black | $9.99 | 1 | $9.99 | Fan Grill |
| 2TB NVMe Drive | $189.90 | 1 | $189.90 | 2TB NVMe Drive |
| NVME Extender | $17.39 | 1 | $17.39 | NVME Extender |
| PWM 4-wire fan temperature controller | $17.99 | 1 | $17.99 | PWM 4-wire fan temperature controller |
| Total | $2,000.92 |
Software
To maximize the performance and efficiency of our cluster, we are utilizing the following software tools:
- MPI Version:
- OpenMPI – v5.0.5
- Linear Algebra Libraries:
- OpenBLAS – v0.3.28 for optimized basic linear algebra operations.
- Compilers:
- GCC – v11.5.0 with optimization flags for x86-based processors.
- Cluster Management Software:
- SLURM (Simple Linux Utility for Resource Management) for job scheduling and resource allocation.
- Spack – v24.05.5.0
- Operating System:
- Rocky Linux 9.5 (Blue Onyx)
Strategy
Benchmarks
-
High Performance Linpack (HPL)
- Installation: HPL is installed using Spack, and OpenBLAS is also installed using Spack. Dependencies are managed within Spack to ensure compatibility and efficiency.
- Configuration:
- The problem size (N) is determined using 80% of total RAM while considering overhead. Based on the formula:
- For Radxa X4 with 8GB RAM, assigning 6GB of the 8GB for HPL, we use N = 38,000.
- For 20 nodes, N is set to 115,000 in HPL.dat to optimize memory utilization across all nodes.
- The block size used is 64.
- For 20 nodes with 4 cores each, we use a process grid of: P = 8, Q = 10.
- Slurm's CPU binding is used to optimize thread placement and prevent core oversubscription. Example command for running HPL on 80 processes:
time -p srun --export=ALL -n 80 ./xhpl
- The problem size (N) is determined using 80% of total RAM while considering overhead. Based on the formula:
- Performance optimization:
- Power settings are adjusted via BIOS or dynamically using powercap-info, setting:
constraint_0_power_limit_uw=5000000 # 5W(default is 6W on the X4)
- The OpenMPI communication between the nodes is adjusted to improve communication overhead.
- The number of OpenBLAS threads is tuned to optimize computational throughput.
- Power settings are adjusted via BIOS or dynamically using powercap-info, setting:
-
STREAM
- Installation and Compilation:
- Installation is done using Spack with GCC, with the source code obtained from the following link: - https://www.cs.virginia.edu/stream/FTP/Code/stream.c
- It is compiled using Spack mpicc:
mpicc -O3 -fopenmp stream.c -o stream_mpi
- Configuration:
- Stream array size is set to the default in the source code, which is 10,000,000.
- Execution and Result monitoring:
- Slurm is used to gather results and verify consistent numbers across multiple runs.
- Installation and Compilation:
-
DLLAMA3
- Installation:
- Install using Spack alongside the OpenBLAS already installed for HPL.
- Using the Spack approach to distribute workloads using MPI.
- Configuration:
- Matrix sizes are still to be decided.
- Storing test data on the Head node’s NVMe drive to ensure minimal I/O overhead.
- Execution:
- The code is executed using SLURM:
srun --mpi=pmi2 -n 80 ./dlaama3_exe
- CPU usage is monitored using Slurm sacct to avoid memory or CPU saturation issues.
- The code is executed using SLURM:
- Installation:
Applications
- Hashcat
- Installation:
- It is built using Spack install, ensuring a CPU-optimized build.
- Configuration:
- Using Slurm, the dictionary will be partitioned across the 80 nodes of the cluster, distributing the workload to run on each node.
- Performance optimization:
- The use of NVMe on the head node as well as the NFS shared file system to avoid memory overheads.
- SLURM sacct, RAPL, and LIKWID will be used to monitor performance, including temperature and CPU frequency.
- Thread concurrency: since the Radxa X4 node has 4 cores, we use 4 threads.
- Installation:
Team Details
Obianyor, Chidiogo – Computer Science senior working on undergraduate research in cybersecurity using a cluster of single board computers (Team Lead).
Roy Garza - Computer Engineering freshman.
Batuhan Sencer - Computer Science – Junior – Has experience with HPL Benchmark(optimization).
Tannar Mitchell – Computer Science – Freshman – I got into HPC through the Winter Classic Invitational Student Cluster Competition.
Ethan Homan – Computer Science Senior working on undergraduate research in cybersecurity using a cluster of single board computers.
Oluwatobiloba Ajani Issac – Information Technology Freshman.